Randomized debugging
Contents
Imagine that you have a project of a medium size, and you need to add a couple of functions to it. The whole system is a complex program, and is debugged by printing traces to a log file. So you've implemented a half of the new functionality, and you'd like to check if that half works more or less correct. Of course, you have a couple of your personal test cases and know how should the resultant execution trace look like. But the problem is that part of your system is a stub, and you can't get the desired trace, when an important part of system is not actually doing anything.
Another case: you have a program that runs in a complex environment, and you want to check how program operates when a series of similar queries to this environment yield specific output. You can, of course, implement a proxy that mimics the desired behavior, but you're lazy, and want to do it faster.
In other words, your program queries the environment or the unimplemented module (we'll treat them equally from now on), and you want--for debugging purposes--to make these queries return specific values without spending too much time for implementing a stub for a query handler. This can be achieved with what I call randomized debugging.
Two kinds of modules
There are basically two kinds of modules.
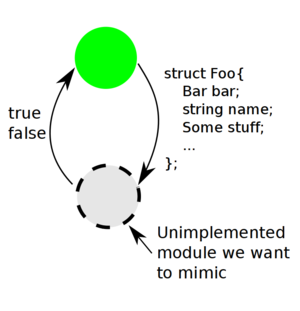
A green module is what we have implemented. A gray module is a stub we want to quickly make.
In the case under consideration, the modules exchange information in an imbalanced way: one feeds the other with lowly ranged values, and the other passes complex structures with an immense range of potential values.
A module of the first kind yields as its output a "tricky" data structure that has complex constitution. If it is such function that is unimplemented in its stub the structures should should be restored keeping all their complexity and consistency. In this case, you really don't have a choice and consider creating a full-blown proxy to mimic its behavior.
In the other case, it's different. A module of a second kind is complementary to the one described above. As its input it gets a complex structure that contains a lot of data. And it behaves as oracle: its result is of a type with a small value range; say, a boolean. The modules of two kinds can behave in a nice pair, as shown on the sidenote picture.
No wonder that such a boolean, provided it is not to flag an "exception" of sorts, branches the program execution dramatically. And it is a specific series of values of these booleans returned which we want the stub to yield, as said in the introduction.
However, since the algorithm is not very simple, and a lot of different factors influence the output (remember, input data are complex!), it would take too much time to implement a stub precise enough. First, we should parse the input correctly. Then, we need to implement a state-machine that remembers what had been queried before and picks up the next result. That's too complex, while we need a fast solution.
The solution proposed is simple. Just replace the unimplemented function with a random number generator. Then run the test several times until the execution trace fits the desired behavior.
"Fuzz testing"? No.
Note, that this is not for testing. This is for debugging; the system is still in not a good shape to test it. Unlike the similar "Fuzz testing" technique linked to by silky in comments (it is to use [semi-]randomly generated data as test input) the randomized debugging achieves different aims. While the former aims catching the untrodden execution paths, the purpose of the latter is to make an unimplemented module to process the given tests correctly in one out of several runs.
The other, "unlucky" runs, when the random generator didn't hit the desired result, might be of some value to the developer, but that's not the aim of the whole thing. For "Fuzz testing" such tests are of primary value, as its aim is to make the program trigger extreme cases. The aim of randomized debugging is to make a system without parts execute as desired with little effort, at least, sometimes.
Where randomized debugging works best
Of course, it's not that good if the function is called several times, and thus you may spent quite a time running the test until it goes well. However, certain programs fit the idea of randomized debugging well. These are the systems that run in a loop, which is terminated when an unimplemented module returns a correct result, the wrong result doing no harm to the processes you want to check.
And of course, the less times the unimplemented subroutine is called, the more effective randomized debugging is. If you call it only twice, and it returns boolean, you'll get the correct execution path in 1/4 cases, no matter if your program is organized in the specific way described above.
Conclusion
Certainly I'm not the only one who noted such a simple way of debugging programs. I'd be glad if you provide links to the similar stuff. But whatever, it's simple and uncommon approach to rough debugging, so it's worth being a blog post. Let alone that at work I successfully used it a couple of times.
Comments imported from the old website
Thank you for interesting link. Fuzzing is a related technique, but not totally same to "randomized debugging". I outlined it in the modified version of the post.
Regarding your idea of an automated fuzzer, I believe that it's not that simple. A related work for some C++ libraries was accomplished by the guys sitting in the very same office as me. The main obstacle is to distinguish failure of the system under test and the failure to compose a correct test (it's noted at the system's page). This problem expands even further, to all sorts of automated test generators that do this by examining syntax only, without any written specification document. No known solution still exists.
Of course, it's more complicated then could be described in this little comment area, I agree. Mainly, it's interesting, if one were interested in such a thing.
If what you're describing isn't Fuzzing (or something similar to it) then I'm afraid I'm having difficulty understanding it at the moment.
What you say in your comment is obviously true; randomly composing correct tests isn't possible without a bit of knowledge of how it should operate (which is plausible).
Oh, if you seem to misunderstand, that's my fault. I'll re-write this post soon, and add some nice pictures for better explanation :-)
Please, don't re-write on my account, I'm often very slow to pick up on things :P I probably just need to re-read it.
Don't worry. At the second thought, I thought that this idea deserves better wording anyway.
Okay. I understand this revised post. In your case I suppose you are not so-much fuzzing input but data. I still consider this a form of fuzzing; but you've alluded to the fact that you work in a place where this kind of thing is your expertise, so I suppose you are entitled to come up with the terminology.
In the case that it's fuzzing data (which obviously is used as input to other areas, but nevertheless...) I'm okay with it, but I don't exactly like the idea of creating test-cases via a "random" method. It seems to me, more logical, to create them piece by piece, testing each component. I would (maybe) like to argue that if you are creating your tests in this fashion (and I know we're just discussing it) perhaps there is a more interesting problem elsewhere to be solved. I.e. perhaps it's not neccessary to do the 'randomized debugging' and instead, perhaps it's better to focus on specific paths that you are about, or design such that these specific paths are more easily accessible.
That said, I again respect that this is your field, and certainly not mine, so I'm not an expert. It's an interesting concept (randomised creation of state) and certainly useful to some degree. But I don't quite think I'd be using it the way you described.
Yes, what you're referring to is commonly called "Fuzzing" (wiki) and it's certainly an interesting component of an overall testing approach, I agree.
It's interesting specifically, because it can be automated. It should be possible, if one were so inclined, to write a fuzzing AOP suite for .NET, (or even just basic reflection-based) that runs across your libraries, generates fuzzed calls, runs them, and saves them if they fail (or perhaps some configuration basis).
Interesting idea.