Why Git is treated as so complex?
Contents
Perhaps, many of these ten readers, who check my blog, are aware that there exists such version control system as Git. There is said a lot about Git in comparison to other tools (here's some StackOverflow threads). Mostly it breaks down to these points:
- Git is powerful
- Git is complicated to use
- Git is badly documented
- Git is incapable to checkout (lock) our Word documents!
It is fairly clear (especially from the last bullet) that no manager would use Git as revision-control tool. Plain old SVN or even CVS would seem a better choice. Perhaps, one of the reasons is that the managers learned it back then, when they were developers yet. But I also think that there is another reason.
Joel and pointers
Joel Spolsky is famous for some of his insightful and somewhat flattering speeches about how software development should be organized. There is one his quote of particular interest, because, in addition to flattery, it is also true.
I’ve come to realize that understanding pointers in C is not a skill, it’s an aptitude. <...> For some reason most people seem to be born without the part of the brain that understands pointers. Pointers require a complex form of doubly-indirected thinking that some people just can’t do, and it’s pretty crucial to good programming.
Joel Spolsky, The Guerrilla Guide to Interviewing blog post, v3.0
I can't say the same with the same confidence level--still don't have enough experience. But, from scientific point of view, to be fair, I haven't seen anything that contradicts it: the best programmers are those who understand pointers.
Git and pointers
And now, what has it to do with Git? Well, everything.
The thing is that the structure of a Git repository is a topologically sorted graph with some pointers to its nodes. And this graph is surely not represented with adjacency matrix, but with pointers as well. Here's a graph of how my local clone of working repository looks like:

(the graph is created with aid of this one-liner)
Each commit has a number of parents, which are pointers, unpainted arrows along the edges drawn (and the convention is that parents are below children). Each tag is a fixed pointer to the commit, and each branch is a pointer that is designated to be constantly moving. The scary rebase thing is just changing a couple of pointers (and commit IDs).
Of course, you most likely would only understand these at the speed of reading if you already knew this. But I noticed also that explaining it this way, though it takes longer time, leads to better understanding and less mess in the repositories, to which less trash is committed. Many seemingly unrelated concepts of Git are better understood if you don't try to elide complexity of repository structure. After a failure to explain this verbally, I drew these pictures to explain what's the difference between pull and pull --rebase (those were referred to in the summary you read in your feed or may read at the top of this page):
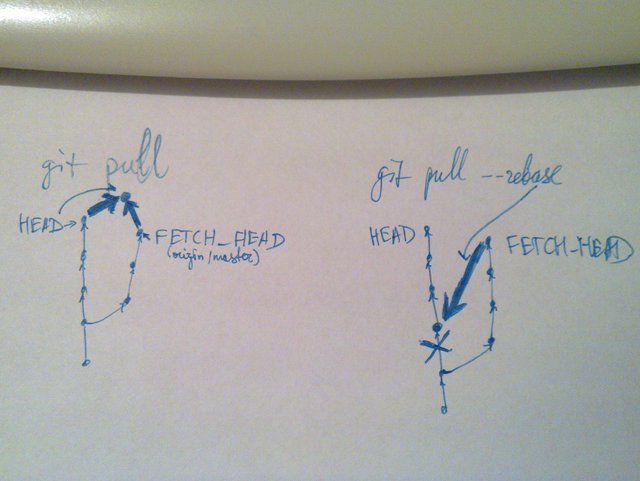
And I think it worked: after that the developer that saw them started to produce much less cruft (contrary to the other guy :-)).
So I think, Git is a rare case when attempts to keep things simple lead to worse understanding. Instead, programmers' "aptitudes" of understanding pointers well should be utilized to provide better though more complex explanation. Eventually, they'll be picked up.
Joel and Git
From this perspective, the fact that Joel actually likes Mercurial, not Git, and has even written a very relevant tutorial on it should have rendered my claims unsound.
Mercurial is said to have the same architecture and be based on the same principles as Git. However, its advantage (personally, I think that it's a disadvantage) is that it smooths sharp corners when developer has to interact with these strange pointers.
Perhaps, that's why Joel picked Mercurial as a basis for the product he promotes with that tutorial (yes, there's an ad in the corner; take a closee look ;-)). If it's simple, it has better acceptance, since more people are capable to smoothly understand how to work with it. As to understanding principles, well, is it really necessary for software to be sold?..
Git and you
The summary is that, if you're a developer that possess a somewhat brain-damaging skill of understanding how these queer pointers work, Git's learning process would be much less hard than it's depicted. No matter what you do with it, even if you don't develop, but just utilize Git to backup config files on your machine, Git's a tool that speaks your language. And as a return of a modest time investment, you'll get a powerful tool that will smoothly bring the way you used to thinking about things into your version control.
By the way, I followed Alik Kirillovich's advice about blogs and added summaries that are displayed in feeds and are separate from the content. Don't you think that they look stupid, unnecessary, repulsive? (I.e. I would appreciate some feedback :-))