Git Cheat Sheet
Contents
Git is a very flexible and powerful tool. I already praised Git a year ago, when I was just starting to love it. Since then, our relationship has matured; although the excitement still doesn't end, doing tricky things turned into routine. In this post I list a couple of advanced tricks we've been doing with Git.
Commit modification magic
Restore commit after git reset
Assume the problem is that you've written a very detailed, elaborate and eloquent commit message, and have just lost it by forgetting to add a file name to git reset COMMIT. Instead of redoing your job, you may just:
$ git reset ORIG_HEAD
Note that ORIG_HEAD here is what you should type verbatim (it's an alias to your previous commit ID, typing which will also work).
Restore commit after a fluke git reset --hard
When you reset your branch head with git reset --hard OLDER_COMMIT, the latest commits are no longer referenced from anywhere. They're still accessible by their commit IDs, so you can do git reset --hard THAT_COMMIT. The complex thing here is to restore the ID of the commit, which you could have forgotten.
One solution is described in the section above, and uses ORIG_HEAD alias. But assume you've done some actions that made you lose it. Another solution solution is the git reflog command that shows the log of reference changes:
$ git reflog | head -n 5
ed9d26d HEAD@{2}: HEAD^: updating HEAD
6619665 HEAD@{3}: merge cluster-quickfix: Fast-forward
ed9d26d HEAD@{4}: checkout: moving from cluster-quickfix to master
6619665 HEAD@{5}: commit: Add a hack to recover failed runs by loading files
ed9d26d HEAD@{6}: checkout: moving from master to cluster-quickfix
ed9d26d HEAD@{7}: merge clusterize-cpa: Fast-forward
This way you will see the last change you've made to your branch head, and may track the commit ID you need by that commit: Commit title message.
Split a commit into two
Sometimes you need to split an old (not the latest) commit into two of them. This is useful when you finally have made your code work, and want to save this result to avoid losing a working version if your subsequent changes would break something again. You make a temporal commit, then several other commits on top of this, and then want to split that temporal bloat when merging your branch back to master. Altering history is performed via well-known interactive rebase, git rebase -i OLD_COMMIT. Let's see how it is used to split a commit. First start an interactive rebase:$ git rebase -i OLD_COMMIT
Then, in the editor spawned, mark a commit you want to split for edit:
pick d19e766 Ignore 'Ignore inline assembler' in CPAchecker traces edit 501d76b Make preprocessing errors not crash all the tools pick 9184d27 Add option tuning to CIL. pick 71c0e10 Impose memory limit on CPAchecker as well pick ed9d26d Add auto-reconnect option to ssh mounts
Continue the rebase by saving and exiting; it will stop at the commit you want to edit, and you'll end up in your shell. Instead of using git commit --amend, as the helper message suggests, do a soft reset:
git reset HEAD^
Now you will make your first commit of those you wanted to split your one into by usual git add — git commit sequence. You may re-use the message of the commit being split with git commit -c ORIG_HEAD. Then, make your second commit gy add/commit; you may re-use the message the same way. After you've made both commits, you may signal git to continue the rebase you're currently in
git rebase --continue
Removing proprietary files from history
Sometimes you need to remove all occurrences of a file from the entire history. The reason may be a copyright infringement or a need to reduce the repository size. Git's repository size increases much when you commit a large binary, and keep updating it. When you replace this binary with the relevant source repository, the history of the binary's updates is nevertheless kept for no useful reason. That's where you need to filter the file out of the history.
The git filter-branch command is a nice tool for that. Unlike the interactive rebase, it keeps the shape of the tree, i.e. retains all the branches and merges. Besides, it works much faster than interactive rebase. User manual for the command already contains the shortcut to use, so you can copy-paste it from there:
$ git filter-branch --index-filter 'git rm --cached --ignore-unmatch BAD_FILE' HEAD Rewrite 4388394c20768ae88957464486d89bc00b2a240a (315/315)
But be careful with copy-pasting! Older versions of Git manual contain a typo, where ' is replaced with `, triggering shell substitution, and leading to weird errors!
Change author name of several commits in history
Another example where git-filter-branch is so handy is changing authorship of several commits in history. This is done via --env-filter option:
$ git filter-branch -f --env-filter ' export GIT_AUTHOR_NAME="Pavel Shved" export GIT_AUTHOR_EMAIL="pavel.shved@gmail.com" ' START..END
Using console efficiently
If you're a bit old-school, and prefer shell to those shiny GUI tools a git community has to offer, you will surely want your console to make you feel like home. Here's a screenshot of my console (click to enlarge):
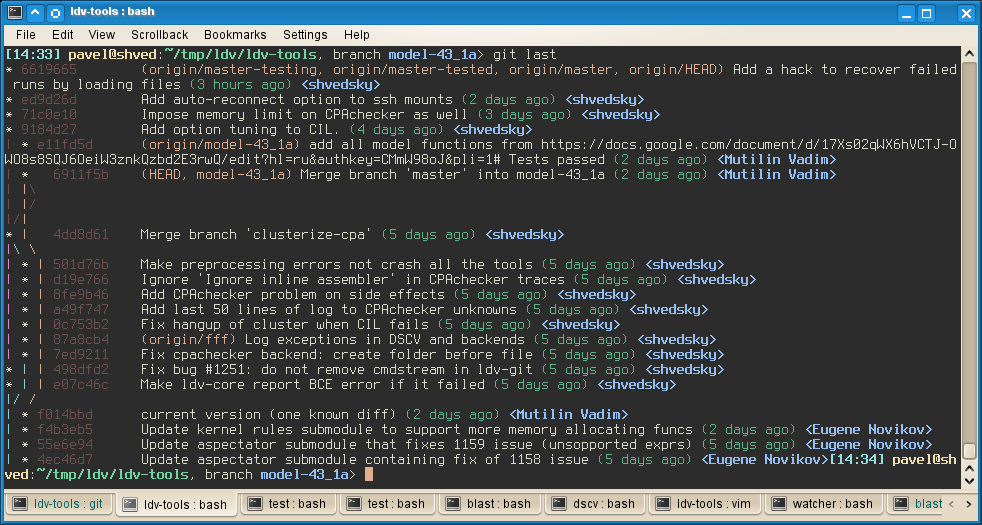
Here's a couple of tips, implementations of which you've just seen.
Branch name in your command prompt
An absolute must-have for every development machine is a branch name in the command prompt. It can't be achieved entirely by means of Git itself, of course. To do that, you should use the relevant capabilities of your shell, and query Git for branch name. Here's how I do it for my Bash shell: I added the following lines to my ~/.bashrc:
PS1="$PS1\$(git branch 2>/dev/null|sed -n 's/^* /, branch \\[\\e[1;34m\\]/p' | sed 's/$/\\[\\e[0m\\]/')"
The console picture above displays shows this prompt (among a couple of other improvements).
Console revision tree
Instead of using a GUI tool to display a tree of commits (useful to see merges, and instead of a usual log), you may use git's capabilities. Just add something like this to your ~/.gitconfig:
[alias]
gr = "log --all --graph --pretty=format:'%Cred%h%Creset%x09%C(yellow)\
%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit --date=relative"
Having been called as git gr from inside a repository, it will display a nice tree, such as the one you see at the console screenshot above.
Note that this format is entirely not helpful for projects with a lot of developers (hence, lots of branches and merges), such as Linux Kernel. This format will take up as much screen width as many simultaneously developed branches there were. However, to list just a part of this tree (such as, several latest commits), I added the following alias:
[alias] last = !git --no-pager gr -20
However, this, unfortunately, doesn't put a newline at the end, so the console is shifted a little
Display file as of a specific commit
With git diff you may easily see the changes you made to a file, but sometimes it would be useful to list the file as it looked like at a certain commit. This is done—surprisingly— with a git show command:
$ git show 55e6e94:shared/sh/timeout
Note that you have to specify an absolute path to the file you're interested in, relative paths do not work.
Discard several unstaged changes
One of the killer features of Git is that you may have uncommitted changes. Moreover, you may control it even finer than on per-file basis with git add -p: Git will ask you if you want to nominate each change you made in a file for committing.
Less known is that git may do the same for discarding some unstaged changes on per-hunk basis. You may discard them all by git checkout FILE_NAME, so why wouldn't it?... Yes, it would: git checkout -p will ask you if you want to keep or discard each hunk, and will forget those you have selected without committing anything.
Without git checkout -p you would have to add everything you do not want to discard, commit, then hard-reset, then soft-reset.
Cherry-pick several commits in a row
Sometimes you need to cherry pick several commits from another branch. The git cherry-pick command, unfortunately, doesn't support specifying several commits to pick, and it's tedious to retype the command or to look it up in the shell history for each commit.
Of course, you can checkout that branch, branch it and perform a non-straightforward rebase --onto. But you may also utilize the power of GNU console tools, and do it much easier.
We can use xargs, which we know is very helpful in parallelization, use -L key, and just type the commit numbers to standard input, hitting ^D at the end. We may copy-paste the commit IDs from a window with git gr or from a log file:
$ xargs -L 1 git cherry-pick ef35196 [master e158b0b] Fix bug when a toolbar is empty 1 files changed, 1 insertions(+), 1 deletions(-) f729f70 [master 2b0d860] Set the default max file size 1 files changed, 1 insertions(+), 1 deletions(-) 3281ffe [master 42b82fb] Refactor template view section 1 files changed, 7 insertions(+), 0 deletions(-) d2c304c [master 462952b] Block software controller routes 1 files changed, 6 insertions(+), 5 deletions(-)
Maintenance in larger projects
When your project is small, you do not have to look for complex commands to perform non-obvious operations. But in larger projects you have to search for efficient solutions. Unless you do it, you would end up manually doing similar things often, as well as each developer in the team will spend some time doing things inefficiently, thus yielding a large net impact on productivity. So, you'll have to automate what you would rather do manually, and here is a couple of hints how to do it.
Integrating other git projects without all their history
You might also want to use submodules to integrate such projects, but then you would have to set up a separate repository for each of the external projects you want to integrate and modify privately. It's not a big deal if you control the repository setup (although the more repositories you are to manage the harder it gets, as you have to assign commit right, set up build servers, etc), but if you use a third-party server, such as GitHub, it is not that pleasant, and involves a lot of noise and manual work.
When doing an open-source project, you sometimes have to include other project into yours (most likely, applying your own patches to them). If they have a Git repository as well, it's a well-known way to include them into your project with a technique known as "subtree merge" (it's well described here, but please, ignore what they say about submodules there).
However, the big disadvantage of this technique is that it introduces the whole history of the thing you integrate into that of your project. Commits made to that project will not differ from commits you and your team made to your project, and it will look like all these people participate in your work (which is partially correct, but not useful to anyone).
You may slightly alter the "standard" subtree merge to make it one commit. Moreover, when you want to uplift the version of that project used in your one, you will be able to do this with a single commit as well. The basic idea is to make a subtree merge, but squash the commit you're making. Here's how I integrated a project from GitHub into shared/ruby/gems/logging subdirectory of our project:
git remote add -f logging-twp https://github.com/TwP/logging.git git merge -s ours --no-commit --squash logging-twp/master git read-tree --prefix=shared/ruby/gems/logging/ -i logging-twp/master git commit -m "Merge of twp/logging commit 123abc from GitHub" git reset --hard
Note the --squash and reset --hard options that differ from a usual subtree merge. A similar difference with the usual subtree merge is in the command to merge the upstream changes in that project:
git pull -s subtree --squash logging-twp master
Auto-tuning of submodules in development setting
When you ship a project with submodules, the pointers to them in the main repository contain fixed URLs to download their code from. However, aside from the public repository, you also have private ones, where the bleeding-edge development happens. The problem here is that all your submodules in all your commits should point to the public repository, while some frest code is temporarily stored in private ones. And you can't check out the code from them! Here's what you'll see if you try:
[14:41] pavel@shved:~/tmp> git clone git://PRIVATE_URL/ldv-tools.git # ...snipped... [14:42] pavel@shved:~/tmp> cd ldv-tools/ [14:42] pavel@shved:~/tmp/ldv-tools, branch master> git checkout -b model-43_1a origin/model-43_1a Branch model-43_1a set up to track remote branch model-43_1a from origin. Switched to a new branch 'model-43_1a' [14:42] pavel@shved:~/tmp/ldv-tools, branch model-43_1a> git submodule update --init --recursive Initialized empty Git repository in /home/pavel/tmp/ldv-tools/kernel-rules/.git/ remote: Counting objects: 570, done. remote: Compressing objects: 100% (405/405), done. remote: Total 570 (delta 286), reused 329 (delta 132) Receiving objects: 100% (570/570), 206.99 KiB, done. Resolving deltas: 100% (286/286), done. fatal: reference is not a tree: 3c9d264cd42cc659544f8dce8e07714eb873efd9 Unable to checkout '3c9d264cd42cc659544f8dce8e07714eb873efd9' in submodule path 'kernel-rules' [14:43] pavel@shved:~/tmp/ldv-tools, branch model-43_1a>
Of course, you can make a git submodule init, and alter the URLs of the origin remotes by git remote set-url origin git://private/submodule.git. However, this would make each team member who wants just to check out the latest revision of an unreleased branch do some manual work, which is unacceptable.
The solution here is to rewrite these paths automatically. As submodules may include other submodules, the rewriting should happen recursively. You may make a recursive alias in ~/.gitconfig that calls itself and rewrites submodule paths. Here's what we use:
[alias]
subinit = !"git submodule init; git config --get-regexp \"^submodule\\..*\\.url$\" | \
sed 's|PUBLIC_URL|PRIVATE_URL|' | xargs -L 1 --no-run-if-empty git config --replace-all; \
git submodule update ; git submodule foreach 'git subinit'"
The respective all-caps words denote the addresses of public and private servers. This wouldn't even be a problem, if the public repository had a per-branch access right, but I don't know if it is possible in Git.
Unsafe branch operations
Sometimes you have to perform unsafe branch operations (such as removing a branch or setting a branch to a non-fast-forward commit). Most likely, hooks would prevent you from doing that, so you'd have to do git update-ref on server. But if your hooks aren't configured properly, you may do it without access to the server console. To delete a branch, run
git push remote :BRANCH_NAME
To force a branch to point to any commit:
git push remote +COMMIT:BRANCH_NAME
It's not that advanced, and is covered in the manual, but still, not obvious.
See the release a commit has first got into
In large projects with a lot of branches merged into (such as Linux Kernel) commit date alone doesn't tell you when a particular commit was released, as it could have been merged to master months after its creation. What could you do to find out the release version a commit belongs?
For that, you could use, surprisingly, git tag command:
$ git tag --contains 94735ec4044a6d318b83ad3c5794e931ed168d10 | head -n 1 v3.0-rc1
Since your revisions are most likely tagged, the list of tags that contain the commit (that's what git tag --contains do) will give you the answer.
Using git-svn
The manual for git svn is elaborate, but is missing a part that explains an instant kick-off. Here's how to:
Start a Git-SVN repo as usual (note that trunk at the end of the first command is not a typo: Git automatically strips one level in this mode):
$ git svn init --stdlayout svn://host/repo/project/trunk $ #OR --> git svn init --no-minimize-url -T svn://host/nonstandard/layout/trunk/cil $ git svn fetch
Now, you shouldn't use the branches Git-SVN has cloned from SVN. You should create "native" git branches for performing development. First check what are the names Git-SVN assigned to the branches, and create a git version of one of them.
$ git branch -r $ git checkout -b GIT_BRANCH SVN_BRANCH $ git reset --hard GIT_BRANCH
My configuration file
Here's my ~/.gitconfig file:
[user]
name = shvedsky
email = pavel.shved@gmail.com
[alias]
st = status
co = checkout
dc = diff --cached
last = !git --no-pager gr -20
pom = push origin master
urom = pull --rebase origin master
ufom = pull --ff-only origin master
gr = "log --all --graph --pretty=format:'%Cred%h%Creset%x09%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit --date=relative"
# Submodule updates
[alias]
sub = submodule update --init --recursive
subinit = !"git submodule init; git config --get-regexp \"^submodule\\..*\\.url$\" | sed 's|PUBLIC|PRIVATE|' | xargs -L 1 --no-run-if-empty git config --replace-all; git submodule update ; git submodule foreach 'git subinit'"
[color]
ui = auto
[color "branch"]
current = yellow reverse
local = yellow
remote = green
[color "diff"]
meta = yellow bold
frag = magenta bold
old = red bold
new = green bold
[color "status"]
added = yellow
changed = green
untracked = cyan
With a bit of nostalgia, I recalled the times when I had a Quake3 config with my own nice tricks...
***
I hope you'll find this cheat sheet useful. I just made it to accumulate all my knowledge and tricks scattered by several notebooks and wikis in one place.