OCaml Hash Table Chronicles
Contents
While preparing the static verification tool I maintain, which is written in OCaml, to the Competition on Software Verification, I noticed a strange performance problem. Queries to a hash table structure seemed to take too much time. Of course, there were a lot of such queries, but a greater amount of queries to a much more complicated data structure, a Binary Decision Diagram, caused the CPU less trouble.
I've been troubleshooting the issue for several hours, and the spot where it hit me was, as a Dr. Watson would say after Sherlock Holmes explained him the case, elementary. Bet let's explicate the case from the very beginning.
What an OCaml hash table looks like
The hash table implementation in OCaml, in addition to the expected capabilities, can also keep the history. So if you add several values for the same key, you may either query the latest value added (via find method), or query them all in the order of appearance (via find_all counterpart). Of course, you can also remove the latest binding of a key (via the remove method), so that the subsequent finds will return the previous value it was bound to.
"Who would want that?" you might ask. It appears, that this feature is very convenient. First, you get a standard library data structure for "a map from something to a list of something" with nearly the same interface as the plain one, without "list". Second, which is more important, when you wrote a multitude of code boilerplates, and only then you realize that not only you need the current value for a key, but, under certain circumstances, the history of its updates as well, you might get really upset. Especially if you use such a strict language as OCaml. Then, you'll praise the opportunity to keep all the code the same, querying the history just where needed.
The latter was what happened in our project. And in this history querying we started to encounter performance problems.
Batteries not included
The first problem was that the standard OCaml hash table interface doesn't have remove_all function that clears the history of a given key! To do that, we had to call remove method as many times, as many values there were for the key. Our profiler demonstrated that it was here where nearly 25% of the runtime had been spent.
I integrated a hash table from "OCaml Batteries Included" project that provided an extension to the standard library. Its hash table did have the remove_all method, and I hoped it would help.
It didn't. It decreased the runtime of removing, but not dramatically; besides, the run times of finds and find_alls remained bigger than I felt they should've been.
Digging deeper...
It was time to dig deeper into the Hash table implementation. But I didn't frown upon that. OCaml is a functional language, and I've been playing with it for quite a while. Sometimes, here and there, I notice strikingly nice implementations of well-known algorithms I learned in the imperative terms (the most nice would be depth-first traversal). No wonder I took a look into its intrinsics.
Unfortunately, hash table is too imperative a data structure for its implementation to look too uncommon. It was a plain array with lists attached to each of its elements.
What was surprising is that storing history appeared to be simpler than not storing it! When an value for a key is added to the table, it's just inserted at the beginning of the bucket's list, and the usual, simple search for a matching key in the list would always hit the latest value bound! removeing the key is as simple: you do the same search, and the first value found is removed, making the value added before it available for the next lookup, just in the historical order.
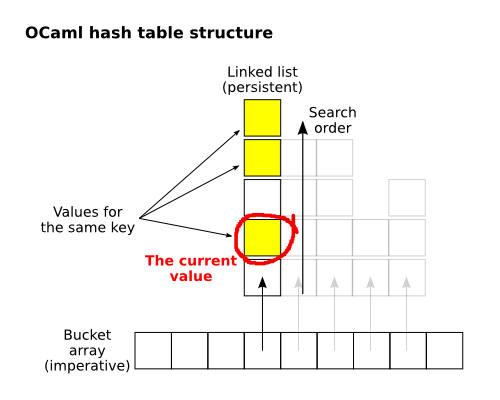
No wonder that our "remove a value for a key as many times as many bindings there were" didn't work fast: its runtime was O(n²), n being the size of the bucket, while we should do it in O(n). Of course, the same worst-case-linear runtime of bucket length couldn't go anywhere, but at least wasting the valuable time in a useless quadratic loop was avoided.
Still, it wasn't fast enough. The integral time to remove all values decreased, but didn't become negligible. Why could that be?
Perhaps, there were just too many values? I inserted some debug prints to the implementation of hash table, and tried to measure how many iterations the remove_all made at each operation. Yes, indeed too many. Hash table bucket size, given a good hash function, should be close to the number of elements divided by the size of hash table's array. And OCaml's standard universal hash function should definitely be good, and it even had a C implementation tuned for speed, apparently. So, the solution could be to increase hash table size.
When the hash table size increase also didn't help, I was quite surprised. How come? I was really lost.
...Until I added a print of hash function values. Yes, they were repeated quite often, and even the keys that were just slightly different had the same hashes—and good hash functions have to assign dramatically different values to slightly different inputs.
I took a closer look to the hash functions, and noticed some magical numbers (10 and 100). What were they?
external hash_param : int -> int -> 'a -> int = "caml_hash_univ_param" "noalloc" let hash x = hash_param 10 100 x
I referred to the documentation, and... uh, I wish it was what I started with!
val hash : 'a -> intHashtbl.hash x associates a positive integer to any value of any type. It is guaranteed that if x = y or Pervasives.compare x y = 0, then hash x = hash y. Moreover, hash always terminates, even on cyclic structures.
val hash_param : int -> int -> 'a -> intHashtbl.hash_param n m x computes a hash value for x, with the same properties as for hash. The two extra parameters n and m give more precise control over hashing. Hashing performs a depth-first, right-to-left traversal of the structure x, stopping after n meaningful nodes were encountered, or m nodes, meaningful or not, were encountered. Meaningful nodes are: integers; floating-point numbers; strings; characters; booleans; and constant constructors. Larger values of m and n means that more nodes are taken into account to compute the final hash value, and therefore collisions are less likely to happen. However, hashing takes longer. The parameters m and n govern the tradeoff between accuracy and speed.
Standard library documentation for hash table, see here.
The keys for the hash value were complex structures (think recursively folded C structures), and many of them shared large parts, which made hash values collide too often. I changed the hash function used for that table to Hashtbl.hash_param 100 100, and the whole table became as fast as a jaguar in a savanna.
Lessons learned
The first thing to see as a morale is that you should read documentation before doing hard debugging. Of course, feeling like a file system hacker is invaluable, but, if you are after delivering something, keeping it slow pays you back in the long run.
When I was writing this post (and it's another cool thing about writing a blog), I suddenly remembered another issue I had with another hash table. The keys also were complex structures, but that table didn't use them directly. Instead, the complex structures were converted to strings, and only they were used as keys. I thought it was too redundant, but the straightforward way, to use the structures as keys, was, surprisingly, slower. I merely rolled back the changes, but now I realize the background behind this. So, perhaps, converting structures to strings (especially when there's a natural 1-to-1 match) helps, as the whole structure will be considered to distinguish.
I realized that keeping the history of hash table updates was not a nice feature at all. Rather, it appeared to be just a small bonus with lack of support in all the aspects (I had to integrate code from the other library to add such a natural functionality as remove_all). Or, it can be used as saving time in return of leaving older unneeded bindings unremoved.
And the last, but not least, I saw a good example how different languages teach you new concepts and new ways to look at the things you're already used to. Such experience, even at cost of half a day, was totally worth it.
Comments imported from the old website
Fahreem, Hash tables are just fine. The key is the hash function.
Most OCaml data are structures that contain structures that contain structures and so forth. This may easily be imagined as a graph. An ideal hash function would traverse the whole graph, and account for all its nodes. However, the default OCaml's hash function does not do this.
The reason is not that it's a bug. Rather, the default configuration tries to make it reasonably fast. It merely assumes that most differences in data structures used as hash keys are close to the "beginning" of the structures, to "roots" of the graph. So itstops exploration at a certain distance (10) and amount of nodes scanned (100), and this makes the hash functions perform both fast and distributed well.
In my particular case, however, the data structures were organized in such a way that the difference between hash keys was "buried" deep inside their graphs. That's why I should have configured my hash differently, because the assumption the default configuration worked well under was not the case. I should have read the documentation, and know this peculiarity.
Now that you have read my post, you know about this without digging through it yourself.
I'm just wondering - if Ocaml hash tables are slow by default in the manner you described, then isn't that a bug?
Regards, Faheem Mitha (faheem at faheem dot info).