Multithreaded Consensus Versus Practice
Contents
Many programmers complain that most of what they've learned in their universities is completely useless in their daily work. Anecdotal evidence, a survey among some MIPT alumni, suggests that the median fraction of courses actually useful to a former student is about 5%. That's like taking one class per week instead of whole week of studying, so could you simply follow those wise brats who indeed spent the whole week smoking weed and boozing?
I'm sure that you simply should look closer. In this post, I tell how a portion of academic knowledge appeared in my work out of the blue.
The Challenge
Last week, we've been trying to improve concurrency of a multithreaded messaging system. When multiple threads wait for incoming messages with distinct labels, one and only one of them has to do the work of parsing the incoming message and directing it to the thread that actually waits for it. Choosing a designated parser thread was not possible, so the waiting threads should somehow assign the work to one and only one of them.
This is not a hard problem, but we had some minor block when we first approached it. So I suggested to step back and take a look at the theory.
That Sounds Familiar
I recall that making several threads designate one and only one of them as a "worker" is called "consensus problem" (Wikipedia provides) a slightly different but equivalent definition.) I also recalled, from my reading of TAoMP ("The Art of Multiprocessor Programming" by Herlihy and Shavit, link), that it was used to demonstrate limitations of various synchronization primitives, and most of them were incapable of solving it. That's right, in the world of formalized computing, some software problems can be proved computationally infeasible. An by "infeasible" I don't mean making a decent AI in first-person shooters, which is definitely infeasible, that's more like Turing machines and Halting problem. So maybe "mutex" is one of the tools that can't solve Consensus?
Who Can and Can Not Solve Consensus
A concurrent object is wait-free if there exists and upper limit N on time/instruction count it takes every call to complete, such that the same limit remains in effect as the number of thread grows indefinitely. Very few concurrent algorithms satisfy this property, and those who do are considered impractical.
Chapter 5 of the book is devoted to assessing relative strength of synchronization primitive operations, and it uses their capability to provide a wait-free solution to consensus problem as a measure of their strength. It later turns out, in chapter 6, that Consensus problem is universal enough to construct a wrapper that turns any single-threaded object into a thread-safe one. So, which synchronization primitives are universal?
Consensus vs. Registers
Assume you only have “simple” memory cells or registers at your disposal, which can turn either way when multiple threads write to them simultaneously. Given these, you only can solve Consensus in a wait-free manner for no more than one thread. (In other words, they are completely useless).
The complete proof is sketched in the book. It's constructed as follows. Assume Consensus can be solved for two threads. At one point, the memory state must be such that the next operation over one of these registers in some thread will determine the outcome. Then all the cases of these operations are enumerated, and viable executions, which usually end up with one thread “running solo,” are constructed. They lead to a situation where the algorithm should return different results based on the same thread-local data, which can't happen.
In particular, this can't happen if you're trying to solve Consensus for two or more threads with simple registers. It is scientifically thus proven that one needs more sophisticated synchronization primitives than just reads and writes to one memory cell. Which could these be?
Consensus vs. Multi-Register Operations
Round Robin Table
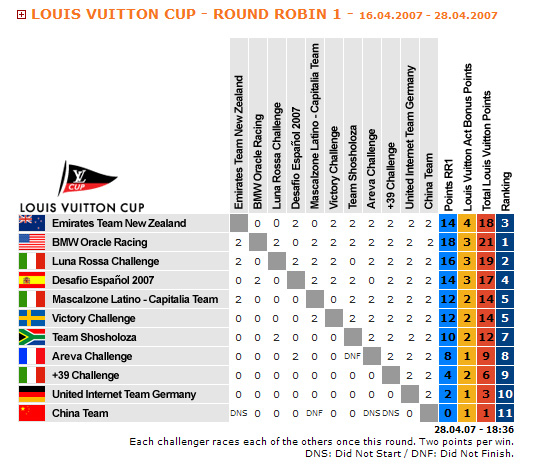
That's a sample round robin table with some competition results. Threads fill a similar data structure concurrently when they solve Consensus with multi-cell atomic writes.
If you can atomically write to N*(N+1)/2 memory cells rather than just one, you can solve Consensus for N threads. The impossibility of solving it for more than N follows the same scheme as outlined in the previous section, but the sample solution is very interesting.
Imagine that threads compete in a round robin tournament; well, not really compete, but simply fill the table with its results. Each game is either a win or a lose, and the score is a number of wins against threads that played at least one game.
When a thread participates in the Consensus, it atomically writes “I lose” in N-1 cells corresponding to its results; it also writes something in the “against itself” cell to distinguish itself from those who did not participate yet. If all threads do that, then, whenever somebody examines the table and computes the score of each thread. the thread who has the highest score will never change. The highest-score thread will always be the same one even if the reads are not atomic, and results change as one is reading the table.
Consensus vs. Complex Data Structures
Section 5.4 of the book demonstrates a proof that synchronized FIFO queues can't solve Consensus for more than two threads. It also claims that the same is true for “many similar data types, such as sets, stacks, double-ended queues, and priority queues,” which I don't have any reason to not believe.
Consensus vs. Atomic Integer Operations
By “atomic integer operations” I mean such functions as swap(&x, v) (set x to v and return the previous value) and compareAndSet(&x, e, u) (set x to u if x == e; do not change otherwise; return whether the value was equal to e) and others. Infrequently used, they are somewhat known to system programmers.
Turns out, these operations are not created equal. For instance, swap can't solve Consensus for more than two threads, while comareAndSet can solve it for infinitely many threads with a very simple algorithm:
Mutex Solution Paradox
The book begins with demonstration how one can implement mutexes using only simple registers. I formulated one of such implementations as a puzzle in my previous post. If we could use mutexes succesfully to solve Consensus, we could have replaced them with register implementations, which is impossible. Does it mean that we can't solve consensus with mutexes for more than one thread? Well, what about this simple algorithm?
More than this, we can implement the all-powerful compareAndSet with a mutex by wrapping the comparison and setting into a mutex' lock-unlock. Yet the book claims it's not possible. How come?
Different Flavors of “Solve”
A concurrent object is starvation-free if every call to its method eventually completes regardless of how threads are scheduled. For instance, an algorithm that hangs if only one thread is (unfairly) scheduled, while others sleep indefinitely for no reason, is not starvation-free per se, but may be such if OS promises not to do this, and be fair. It is weaker than wait-freedom because it doesn't require a global bound on the call length.
The mutex-based consensus algorithm is only correct if mutex has strong enough progress condition, for instance, if it's starvation-free (wait-freedom is not required here; see the last exercise to the Chapter 5 in the book). Mutexes implemented with simple registers are not starvation-free hence they don't completely “solve” Consensus. The theoretical results on impossibility given above only provide proofs for wait-free algorithms, however, it depends on the actual implementation of mutex whether the resultant algorithm will be wait-free or not.
It indeed is a corollary of the results discussed above that you can't make a starvation-free lock with simple registers only. Threads in such locks usually “spin” waiting for the memory to enter a state that signals this particular thread (and only it) to enter the critical section. If, at this point, some other thread “runs solo,” you are stuck forever. If you apply the register "weakness" proof scheme to a register-based mutex, this infinite loop will eliminate the contradiction that same thread-local data will lead to different results: they'll lead to endless spinning instead. Notice how that's not the case for compareAndSet() solution to Consensus presented above.
So the resolution to the paradox described above is that the mutex-based program is a solution only if the underlying mutex is starvation-free--in addition to simply being a correct mutual exclusion algorithm. To implement a starvation-free mutex, you need to have compareAndSet or similarly strong primitive operations, but they may be concealed within the lock or the OS implementation, and don't have to appear in your program explicitly.
Consensus vs. Humans
Consensus and Humans
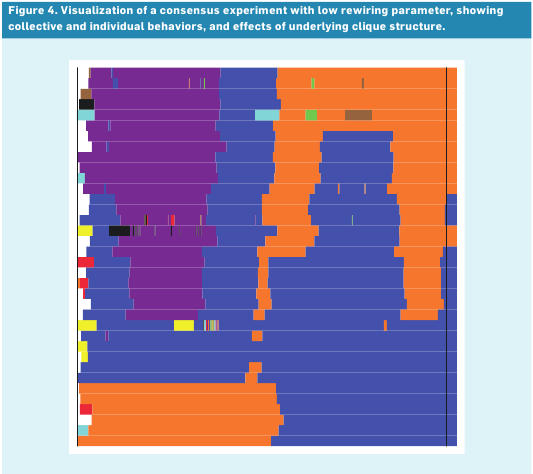
Here's how choices of individual subjects changed over time during the experiment on how humans solve Consesus. Read more here.
Another interesting example of a computational system that can's solve consensus problem is a social network of human beings. A group of researchers conducted an experiment where several people were given material incentives to reach a specific consensus (an equivalent of threads proposing their own value), and were set out to reach one. They could not communicate in any way except for announcing the current value each person agrees to to their neighbors, i.e. they didn't have a designated leader or a common strategy.
The experiments demonstrated that people can't reach consensus in this settings. An interesting finding, though, was that the subjects quickly created a "bipartisan" system with only two colors, and started to juggle them around. Sometimes, new colors appeared as an attempt to unite under a different color, but these attempts quickly died off. Doesn't it remind of anything?..
Unsurprising Conclusion
So, it turns out, the theory didn't help us much with the original task. It helped us understand that thread nomination is a separate, studied problem that can be solved given the right tools. However, our initial choice of tools, the "mutex" was correct, and the knowledge of theory couldn't improve our initial choice. I'm glad it made me read "The Art Of Multiprocessor Programming" book more thoroughly than I otherwise would, and I do not consider it a waste of time. Multicore computing is getting more ubiquitous, and knowing the theory won't hurt.