Misuse of Caching in Web Applications
Contents
I noticed a pattern in some of my web software architecture failures, and I also notice similar pattern in others' designs. In many cases, people simply misuse memcache, hurting performance of their web applications.
If performance is your goal, you can’t pretend that your computations and rendering is fast, and add transparent caching where it later appears to be slow. Transparent caching is a fairy tale programmers have been telling one another, and we’ve also been writing tools and building hardware to remain in for decades. Turns out, it doesn’t scale. A high-performance web application is designed around serving static content that--sometimes--get recomputed
- under very specific conditions;
- only partially;
- after very specific events;
- most likely, by a component separate from the one serving the content.
Where would you keep such a static content derived from the raw data (I will later call it ”derived content”)? Memory caches are often unfit for the job of storing derived data: your items may be removed from cache ("evicted") if you don't have enough memory, or if your another web application or component is working within the same cache. And evictions are much more severe than you might think.
Assume it takes your webapp several seconds to recompute the item you want to serve even if it hasn’t changed, and all requests that come during this period are going to have at least these several seconds of latency. In modern multi-component web-services high latency for a small fraction of requests makes much more harm than it seems, as corroborated by this overview paper by Googlers, so you might want to avoid it. Not to mention the simple reasoning that if this eviction happens under heavy load, the stack of HTTP requests waiting for the data to be computed might kill you.
Is there a problem with caching data altogether? Yes, and no. The idea of memoization--storing results of complex computation for later reuse--is perfectly fine. The problem with caching as I see it is that many now view caching exclusively as storing data in unreliable but fast-to-access caches (think memcached). This is not how caches in web applications have to work despite that’s how they usually do.
Caching Primer
There is another storage you can use for precomputed results, the Database (SQL, or NoSQL, or NewSQL) where you probably store the rest of your data.
Assume you are presenting users with a set of analytics over the data they entered yesterday; say some breakdown of yesterday’s sales by zip code. Say, it takes 20 seconds to compute all the data. Where would you store it?
What you could do is to cache the result of the first request, spending 20 seconds to serve it. You can be smarter, and add a cron job that hits that page every midnight. But if your data gets evicted, your next user will suffer these 20 seconds.
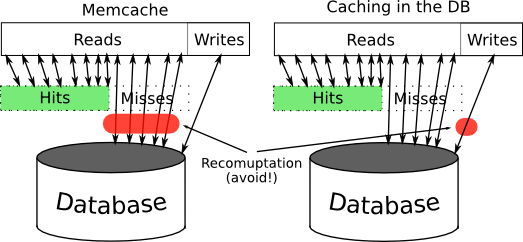
Instead, store the data in your persistent storage (database), the storage query being triggered by the same daily cron job. When the user requests the analytics, just serve it from there; it will never delay by 20 seconds since the data aren’t going anywhere unless you explicitly delete them, which you’ll be wise not to do needlessly. It will take you one database query to retrieve the results, and you can also cache this query in memcache for even faster results. No 20-second latency anymore, just the latency of one database select of a single row. Neat, right? Here’s a lame picture to illustrate this that shows that recomputing-on-write is more efficient as writes are less frequent usually:
Why People Use Memcache Then
So if the world of using permanent storage for caches is all ponies and rainbows, why isn’t it used everywhere? The reasons are performance tradeoff, abusing unreliability of caches, and simple storage management.
Preformance Tradeoff
If your computation is as fast as querying storage, there’s no sense to use persistent storage as cache. In rare cases when you have insufficient latency, but overprovisioned on CPU throughput persistent caching will improve your app, but most likely not. Also, if you think of updating cache often in background as triggered by user requests, you need a fast task offload solution that avoids write contention (sich as App Engine’s Task Queues).
Abusing Cache Unreliability for Eventual Consistency
Cache expiration algorithms make the state of the cache eventually correct with respect your changing data. To build a correct permanent storage cache, you must make sure that the data in this cache are explicitly updated or deleted if unused. Unreliable cache will recycle stale data for you: if a key is never going to be accessed, it will be simply evicted in favor of more recent keys without occupying extra storage. Impersistence of memcache is an asset rather than liability in such cases. One of my previous posts, about sharded counter, contains an example of this.
The problem with efficient record recycling is that you can’t update record’s access time in the persistent database every time you access it without significant performance penalty (see the previous section on fast task offloading). On the other hand, you implicitly do this on every access with specialized in-memory caches. In some cases, a background recurring thread that performs DELETE FROM cache WHERE created_at > NOW() - 600 will take care of this, but this isn’t always possible.
Automatic Storage Management
A memcache can successfully and automatically operate when you don’t have enough memory to store all the results. Its efficiency doesn’t roll downhill with the pace increase because more frequently accessed entries stay hot, while performance suffers only on less “hot” entries hence rarely. Finding space for storage of one extra column per database row is rarely a problem today, though.
Narrowing Down the Scope
Given the above limitations, storing intermediate results in database makes perfect sense when the cost of computing these results is greater than the cost of database query, and when the data are tied to other database records. Say, storing a pre-rendered version of a blog post or a wiki page that uses a custom markup (especially if it’s badly implemented like the one in this blog) makes sense: you simply update it on write, and remove if the post is deleted. Storing a result of 10-minutes analytics query in a table rather than in a cache also makes sense (and some still rely on memcache to hold such data). Storing a join by key of two SQL tables is probably not worth it.
You need to design your application so that it is capable of making derived data updates after writes. Relying on caching will hurt you in the long run, because your application will be improperly architectured.