Nonlinear Effects when Web Server is at 100% CPU
Contents
I used to wonder what this Error 502 meant when I observed when I visited my favorite websites. When I retried the error usually seemed to disappear, and I found it's linked with the service being overwhelmed with requests at certain times. But why do I see it? Why doesn't the web server start many threads leveraging OS capabilities of CPU sharing? If it queues incoming requests, why doesn't it just delay their fulfillment, just making them wait in a line longer? Just like, you know, in any cafe, bank, and public office where people form lines, and get what they needed--eventually?
There are three answers to this. First, small-latency error is more important than serving all requests. Second, there are interesting nonlinear effects that happen when the server is at capacity if you aren't using queueing. Which leads to the third point, if more requests arrive than what you can process in one second, you will not be able to serve them, ever. You have to drop them. Let's take a closer look.
Fast error is better than slow result
If a service is consuming responses of several other services, it's often in a situation where it can ignore output of one of them, and still provide value to the user. An example in the paper linked above is Google web search that can skip displaying ads, maps, and other additional information, and simply serve search results.
This alone could be a good reason to drop a request, but this doesn't sound that convincing for the frontend server that faces a human end-user. Let's explore two ways of keeping the requests.
Latency Grows Exponentially If You're Not Limiting Rate
Imagine we're not limiting the number of worker threads, and just start processing everything we receive. In other words, we do not keep a queue of requests, and rely on the operating system to provide fair distribution of computing power among working threads. Say, if we have 4 cores, and every requests takes 1 second of CPU work, we can serve at 4 QPS; this is considered "at capacity".
What would happen if a rate grows beyond 4; say, to 5? Requests arrived at the beginning would not complete when a pack of new requests arrives. At the beginning of 2nd second, 5 earlier requests each would have 20% left, and execution speed would drop twice, so they would be completed only after 1.5 seconds. At the beginning of second 2, requests that arrived at second 1 would have completed in 0.4 seconds, but 5 more requests arrive, decreasing the speed by a factor of two again. The latency for these requests would be 2 seconds. The latency for the next pack arriving at 3rd second would be as much as 2¾ seconds, etc. Here's an illustration on how CPU time is distributed among requests, requests arrived at the same second have the same color:
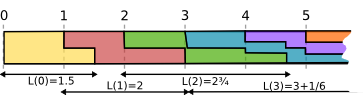
Let's assess how the latency grows with rate. In other words, let's compute function L(t, r), latency of a request arrived at the moment t if the rate of requests is r times higher than capacity. For instance, if our capacity is 4 QPS, but there are 5 incoming requests, then the rate parameter r = 1.25.
First, the number of in-flight requests at the beginning of a given second N(t) grows linearly with t. Indeed, N(t) < QPS*t; on the other hand, the amount of CPU time owed to previous requests is QPS*t*(r-1)/r, which equals QPS*t*(1-1/r). So, (1-1/r)*QPS*t < N(t) < QPS*t, which means that N is linear function of t, e.g. N(t) = a*t, where a > QPS*(1-1/r).
Second, the CPU time allotted to a request witinh a second [t, t+1) is at most 1/N(t). The latency of the request is then the minimal x such that S = 1/N(t) + 1/N(t+1) + ... + 1/N(t+x) ≥ r. Since N is linear, this sum equals to 1/(a*t) + 1/(a*t + a) + 1/(a*t + 2a) + ... 1/(a*t + xa). From integral calculus we recall we can approximate the sum 1/2 + 1/3 + ... + 1/x as ln(x), so S ≅ 1/a * (ln x - ln t)). Hence, x ≥ t * exp(a*r).
We proved that L(t, r) ≳ t * exp(a*r) where a > (1-1/r), so latency grows linearly with time, and exponentially with rate of incoming requests if we try to serve them all right away.
Newly arriving requests slow down the currently executing ones, prolonging their latency. There is a way to mitigate it: queueing.
Latency Grows Linearly with Queues
Imagine the most naive solution: first come, first served queue. All incoming requests are stored in the queue, and are served in the order they arrive, handler popping them from the queue as soon as it has capacity (a free CPU share or an idle working thread).
When the server is below capacity, the queue is always empty, and the latency of each request is L0, which is the time it takes handler to construct a response. What happens when the server reaches capacity? The latency of a request that arrives at time t (we assume constant rate r) is L(t, r) = Q(t, r)*L0 + L0, where Q(t) is the queue size when the request arrives. The size of the queue is the number of undone requests, which is t*(r-1). Therefore, L(t, r) = t*(r-1)*L0 + L0, concluding that latency grows linearly with both rate and time with queues.
You Can't Serve More Requests than What You Can
This may seem obvious, but is often overlooked. If you start queueing requests and serve them later, then you need to have the capacity dedicated to these requests later. Meanwhile, the next second more requests arrive than you can serve that second, and you have these old requests, too. Now you have three options:
- Serve old requests first, but then your latency will start growing at least linearly as you spend more time over capacity;
- Serve new requests first, but then old requests will remain in the queue until the first second where more requests arrive. In most cases, this would mean waiting hours as usage pattern are usually circular.
- Discard some requests without spending CPU time on serving them. Which leads us to error 502.
In other words, we have to drop (r-1) of all requests regardless of which scheduling mechanism we use. Whether or not the latency grows linearly or exponentially is irrelevant: it has to grow, and this is bad. Its exponential, turbulent growth without queueing is just an interesting artefact because you have another reason to avoid starting all the incoming requests at once: it would simply choke OS scheduler.