How to Literally Ask Neural Network for Help and Watch It Deliver
Contents
This is one of the small fun things I’ve learned while working on writing a face detector from scratch for the v2 of the Smiling Bot.
Single-Shot Detector, like many other detectors, employs Non-Maximum Suppression at inference. Usually, it’s implemented using a greedy algorithm: sort all boxes by detection confidence, take the top, discard overlapping, repeat.
So I noticed in my model, the box with the highest detection confidence was not the box that had the best fitting offsets. Often, it would overlap with the face but partially. However, this poorly fit box would suppress other boxes that had a better geometric fit.
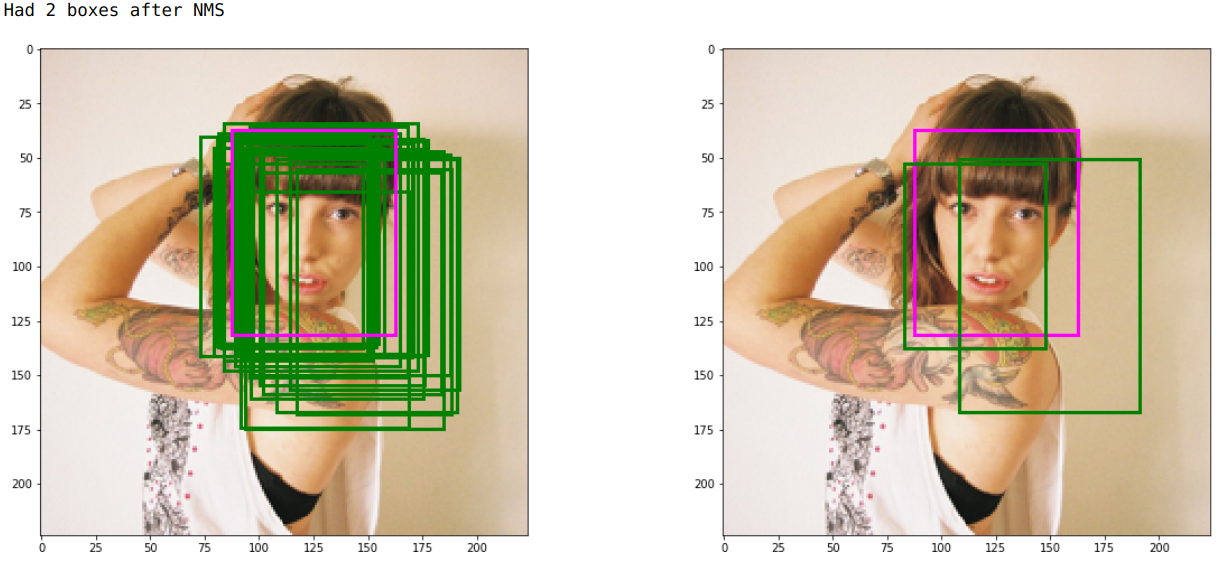
E.g. in this image (on the right), the box that contains the right part of the face (and a lot of non-face space) has the most detection confidence, and it suppresses most other boxes. (The green boxes are the predictions, the pink box is the GT). That “best” box fits the face so poorly that another, second box for the same face survives the NMS. Indicatively, that box approximates the face better.
Essentially, I want my model to stop optimizing class confidence once it’s very confident that the detection is positive, and to start optimizing for the box offsets more instead.
You know why I like neural networks? You can almost literally talk to them like you talk to people; you just need to speak tensors. I literally added the lines “if class confidence is high, put more weight to the offset loss” (here’s the commit), akin to this:
detection_confidence = tf.reduce_max(
tf.math.softmax(class_logits_pred * gt_pos_cls_mask, axis=1),
axis=1)
# Find rows that both have "positive detection GT" (gt_pos_mask) and
# have high detection confidence.
mask = gt_pos_mask & (detection_confidence > 0.999)
box_params_focus_mask = expand_mask(mask,
self.detector.num_box_params)
L_extra = (alpha_extra *
smooth_l1(y_pred_params * box_params_focus_mask,
y_gt_params * box_params_focus_mask))
loss = 1.0 / num_matched_boxes * (L_conf + alpha * L_loc + L_extra)
#After training, the most confident box did fit the face geometry way way better (as did the other boxes). It worked like magic.

Well, ok, it was more like a magic show that a magician puts out: it looks magical but you know a lot of work
went into making it look exactly as smooth as it is. E.g. the reweighing factor alpha_extra here was pretty
sensitive. “More weight” here actually just meant edouble the offset loss”. Larger values made everything
unstable (I started with the factor of 10), and who knows how sensitive this value will be in the further
experiments.
I also tried other things that didn’t work, e.g. using max of the two loss components $L_{loc}$ and
$L_{conf}$ to keep them the same. This increased the training time significantly, and required a very
precisely set weight (195.0-200.0), so I abandoned this approach. I rationalized it as that the max
operation simply picks either the class confidence or the offset loss to train on at each step, and thus
results in slower, less stable training for the same objective. Meanwhile, for that slower training to work,
I had to increase the offset loss weight facto. So in fact, this just implements training for the same
objective but with a 200.0 weight for the offset loss.
In other words, the show was put on by a professional magician for sure, with ablation studies no less!
But moments like these, when you get to add something of your own to following someone else’s lead (even if it’s just fine-tuning one parameter here or there) is what makes the life of a Machine Learning engineer really satisfying.