Writing Neural Face Detector from Scratch (sneak peek)
Contents
After working on perception models at late-stage startup, I realized there are large parts of these models I didn’t even touch and didn’t know existed. These pieces were working well, so why touch them? Naturally, this means I’m missing out on education opportunities one could only get when implementing something from scratch. (That’s partly why I want to join a younger startup today).
What to work on? I remembered there’s something I could improve on my smiling bot:
- Its non-neural face detector is slow to the point it puts my manliness in jeopardy;
- The two-stage detection pipeline is not accurate enough.
So I took on a challenge to write a deep neural face detector without peeking at reference implementations without asking for help, and without any templates / codelabs / tutorials that would guide me through this process. And unlike in the previous iteration of the Smiling Bot project, “good enough” would not be an answer this time. The model must work well and it must work fast.
I’ve learned quite a bit about deep learning model debugging, about Tensorflow 2.0 and tensor operations (I’ll write separate posts on those). And importantly, I’ve learned how long it takes to perform an undertaking like that (~2 work-weeks for me).
So while there’s more to write, I’m just really really happy that I was finally able to train a model that actually works on the validation set. I know there’s more work to do, and I’ll fine tune it later, but here’s how I feel right now:
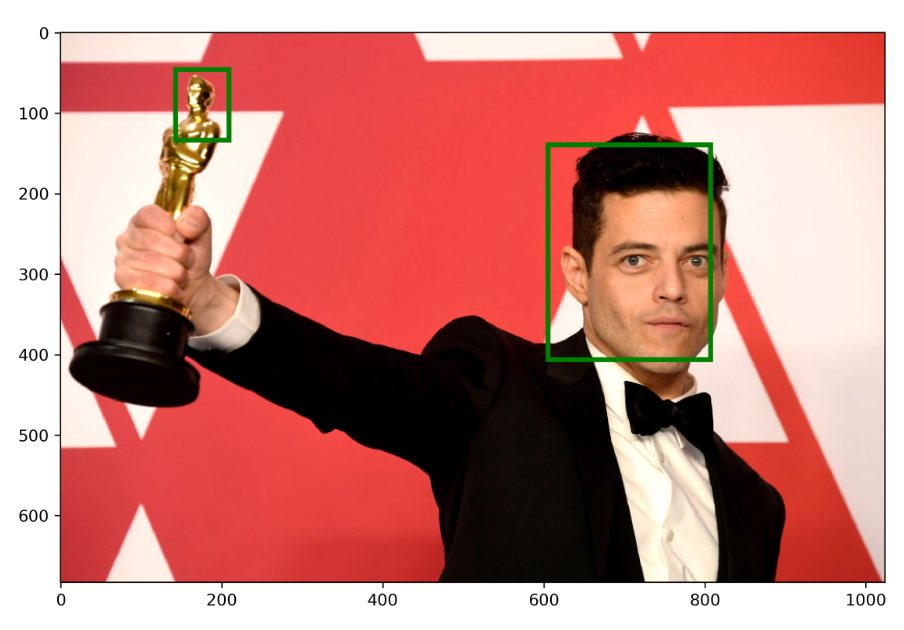
Ok, this is an image from here that I couldn’t help but run through the most recent iteration of my face detector :D
Please do not look at its code located here 🤫 It’s not ready yet!
Why would it be faster?
The smiling/not smiling classifier in the Smiling Bot v1 already uses an AlexNet-based convolutional model.
However, fast single-stage detectors like SSD can perform both object classification and detection from the same feature map. There are two-stage detectors as well (e.g. YOLO) that don’t add much tax to that.
YOLO papers (e.g. YOLO v3) are sometimes written in a refreshing, no-frills, no-bs, Reddit-commenter style science.
Check out the page 6 from the PDF. Look, I agree that the style is uncanny, but I sometimes would like to see exactly these insights from the authors of many papers I read.
Thus I decided to build an SSD detecor with AlexNet backbone first, and then take it from there.
Why SSD and why bother with AlexNet?
This choice is a bit strange, especially AlexNet few people use. But it’s not the final architecture. When building a very complex system from scratch, I try to build it one piece at a time, and move on to the next piece when the first piece is proven working.
I already have a dataset where I know AlexNet works well. Out of all detectors, SSD seems like it has fewest moving parts (except the Transformer-based detector released a month ago by Facebook, but I wanted something more proven). So here’s how we change one thing at a time:
-
Create a dataset with both detections and classifications. Prove AlexNet still works for the full-image classification.
-
Attach SSD detection head to the AlexNet as described in [Gu et al, 2017] . Prove, essentially, that my dataset has enough training data to perform detections.
-
Move the model onto the device. Prove that I can do detections on device.
-
Either
- Use another model for the backbone…
- …or use another model for the detector
- …or use another loss function…
- …or do something else cool.
but not all at once! This way, I can debug these “modules” one by one.
-
Once this “module” is ready, change other modules while constantly deploying on device.
Why would it be more accurate?
I think part of the issue with the original Smiling Bot’s model is the small training dataset. I only have ~10,000 labeled images of smilinng / not smiling faces. Dataset of this size is nothing to write home about.
But I can get way more training data for just faces, without knowing their emotions, and use transfer learning. After training the SSD face detector, I plan to “sneak in” another class to the output and fine-tune on the smile / no smile dataset. My hope is, the features learned for face detection will be useful for face classification as well.
Where would I get more training data for faces if I don’t want to do labeling? Here’s where knowledge distillation comes into play.
Distilling the Ground Truth from a different model
I didn’t want to order labeling of the face data, so I just used an existing face detector (MTCNN) on the whole dataset to generate the ground truth for the face detector and (the original Google Face dataset didn’t have many faces labeled at all). It didn’t label all the faces, but let’s be honest, neither would be the human labelers.
So at the expense of just 130 lines of code and a small visualization, I had 100,000 images labeled with face detections.
On the first sight, the heuristic, imprecise ground truth makes no sense, but it works. This something that I struggled to grasp in the past (and I had to trust more senior modeling engineers) until I witnessed it myself today. Deep models are good at generalizing heuristic, imprecise ground truth.
On many images from the training set, the deep model I’ve trained was able to detect faces correctly even though the GT had no faces labeled. The model wasn’t able to effectively learn that there is no face on those images. In fact, now I also know that if I wanted it to not detect faces on these outliers, I’d have to try really hard (batch balancing / loss amplification / extra outputs).
After this experience, I also have renewed trust in Snorkel and other weak supervision techniques.
Future work
Well, this is just the beginning, but writing down my plans helps me evaluate them :)
Setting up for Success: Faster Features, Flease!
There is no point in iterating over this dataset without reducing the CPU time. The current pipeline generates features concurrently with training. The feature generation currently works like so: on the CPU,
for each image in the batch (x 32)
for each scale (x 2)
for each anchor location (x ~1000)
for each anchor (x ~4)
is IOU < 0.5 ?
then adjust features and masks.
…and all of that is Python! Running ultra-fast inference and backpropagation on the GPU is way faster than this. This lands on the wrong side of the Training Balance Equation, and the GPU usage is literally indistinguishable from 0%.
I could do two things here:
- Save the dataset on disk and use that dataset to tuen the architecture.
- Come up with or find a faster GPU-based algorithmm for box matching (I don’t know if one exists yet).
I would however opt for the faster GPU algorithm here, for the following reasons:
- The Anchor-based detector feature set is closely tied with the network architecture. If I wanted to iterate on the number of anchors, number of classes, IOU thresholds, it’d have to re-generate the dataset.
- Even when generating the dataset, why not make it fast as well?
- Learning more cool GPU algorithms is totally better than writing data pipelines.
(Update) Ok, so I’ve implemented that. Not only had I to make the anchor matching parallelized but I needed to move image resizing from ImageIO to TensorFlow. Here’s the commit that contains all changes, and now my GPU usage is finally at 40% compared to 0% before. I think I’ll be releasing these utils as a separate library.
Build an Inference Benchmark on Raspberry Pi
Once the quality baseline is established, I need to establish the latency baseline. It’s not enough to count flops. The latency of networks heavily depends on their weights. For example, all neurons will be activated in a randomly initialized network, but in a trained one ReLU zeroes out most values, which leads to faster computation in the downstream layers.
So I’m going to deploy the model onto the device, and establish the “operations per second” tradeoff for trained convolutional networks, and go from there.
Explore different models
Once I establish a baseline for the performance and latency using the AlexNet backbone, I can move on to other network architectures. There’s no shortage of them to try: DarkNet, MobileNet in addition to the traditional ResNet. But sinnce these architectures aren’t what I tried before, I need to have the rest of the pipeline working so I could isolate the failures.