Deleted functions in C++0x and binary compatibility
Having read a recent version of C++ ABI standard, I noticed that certain bits of it were revised (the version of the standard hasn't nevertheless been changed). Particularly, a vtable entry of a mysterious "deleted virtual function" was documented. I thought that it could influence binary compatibility, and here's what I found out.
What deleted functions are for?
C++0x introduces another form of a function definition -- deleted function:
When a function is deleted, it means that calling it is prohibited, but substitution of it is not a failure. This is mainly to be used instead of making constructors private and providing abort()ing definitions to them (to explicitly prohibit copying objects, as in example above):
Another use-case is to prohibit certain type conversions. The use cases are well described at the relevant wikipedia entry.
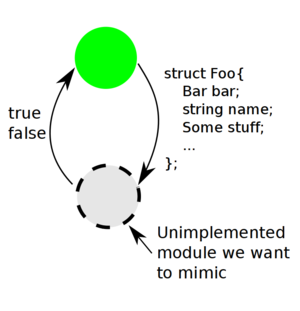
In other words deleted function means "the function is declared but it actually doesn't exist."
What is SFINAE?
SFINAE is an acronym for Substitution Failure Is Not An Error. It is used for tricky compile-time template-based lookups that add a lot of flexibility to C++ language. The most obvious case, from the Wikipedia entry is this:
However, sometimes SFINAE seems to empower C++ beyond imagination of an average C++ programmer. It can be used to:
- Call function if it exists or do something else if it doesn't
- Call member function only if the object has it ("Use Ruby," you say?)
- Distinguish POD and non-POD types
Yes, C++ can do this; with pain and squeak, but it can. A good explanation of WTF??! can be found here.
That's all it could be used for. It can't benefit SFINAE, since deleted functions do not influence lookup rules, so a deleted function should be considered a proper substitution; this, in turn, leads to compile error because deleted functions can't be used in any way, even if they're not called. However, this sometimes is of benefit, since we may want certain lookups to fail, instead of silently picking a badly-working substitution.
So the main purpose of deleted functions is additional compile-time checks. Not even altering the way a code that uses certain functions and classes works, but mere checking. However, hiding constructors arises issues that concern binary compatibility. Let's check if there's anything interesting.
Binary compatibility issues
In the problem of binary compatibility we consider two versions of a C++ library: A and B. We try to write B in such a way that any program built against A lib keeps functioning if there's just a B library in the system. I usually restrict it to GCC compiler, because I don't know much about the other ones :-) (and because of the means described in the other blog post about C++).If a function is declared deleted, then a) it's considered inline, and b) it can't be called by a complying program.
The property b) is interesting since it influences source-code compatibility. In my research I assumed that binary compatibility of libraries should only be retained for source compatible programs, i.e. for those which compile unmodified with both versions of a library.
This means that if from a deleted function in library A the delete specifier was removed in library B, then it can't influence anything, because that function wasn't referred to in any program built against A library. Moreover, if it's the case of a virtual function, the claim cited above of ABI standard makes virtual table not change in size.
This also means that if a function gains delete specifier in B library, the source compatibility requires all programs that are built against A library... just not use that function. This means that anything can happen on binary level (note again that a slot in vtable is kept) with this function, and it won't influence any of older programs.
API modifications: would delete help?
So for source-compatible programs deleted functions introduce absolutely no problems. I'd like to refrain from analyzing source incompatible programs, because, strictly speaking, we could then dive into unfruitful analysis of compatibility of sound library and instant-messaging libs.
However, there are practical patterns of API changes that break source compatibility but still make sense. For example, we want to deprecate a function, so that newly linked programs (against B library) will use a safer equivalent, while those linked against A will keep working. Would delete be of help here? (That's actually the first thing I thought about when I saw delete modifier).
Unfortunately, it wouldn't. Deleted function don't have a body; it's just not emitted, because they're inline and... erm, inapplicable to calls, by definition. Moreover, providing a body for a function previously declared "deleted" is a violation of one-definition rule. So, unless you're doing dirty hacks, when the header you compile library with and the header you expose to user are different, you're out of luck here.
What would help is making functions private. If you want to safely "delete" your virtual function, you should just make it private (and ditch all references to it from your internals, of course). The virtual tables won't change in any way. For non-members, where "private" is not available, the best you could is putting a line in your documentation "DON'T CALL THIS!"
Of course, after some time you may declare your function deleted thus making all programs that still use it incapable to start (dynamic linker will signal unmet dependency). If the function was virtual, no problems with virtual tables will arise as well. That seems like a sane and safe deprecation method (normal-private-deleted).
No problems may arise if a private abort()ing function was declared deleted in the new library version. Such function couldn't be referenced from the complying programs (unless you for an insane reason did this in your public inline member functions). So no dependency on their symbols would be introduced.
Conclusion
The first thing I thought when I saw a delete specifier was, "Wow, that is probably cool stuff for binary compatibility!" Indeed, it helps to remove obsolete functions (and break compatibility if it's intentional), but in most cases (when it's non-virtual) it's no different from just removing this function. So deleted functions don't bring any new concepts to binary compatibility. Nevertheless, to be fair, they don't bring in anything harmful as well.
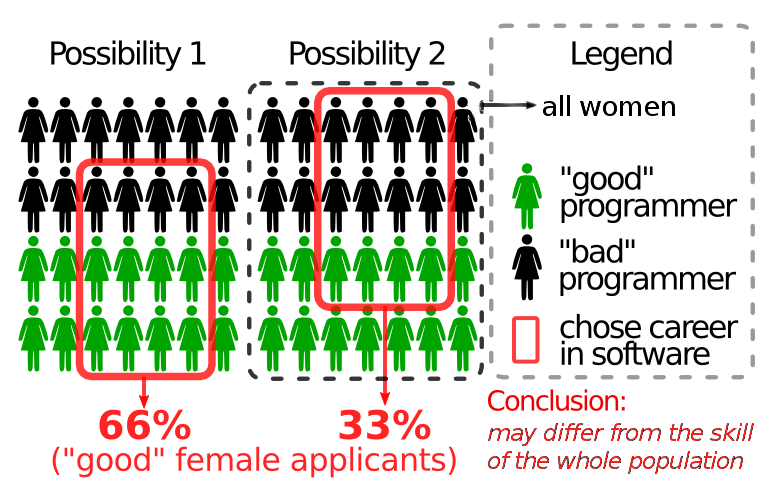
FWIW I think your post is needlessly argumentative. The reason there are useless flamewars on this topic is not because of a lack of understanding of math, it is due to the way it is framed.
Even your mathematically framing is not great. Consider that if you select, from the group of all male programmers in the industry for more than 6 years, and the group of all females of the same range, and compare. You may find that on average the female is better. Why? Because they've had to be more dedicated to stay in the field.
It's easy to bias the selection to get any outcome you want, really.
The question is more readily addressed by clarifying down to points. For example, who has better ability in maths? Who has better ability in translating desires (specs) into code? Who has a better problem-solving and debugging skills? Only this way can you get to specifics, and get useful metrics. Arguably useful anyway.