Fail Early, Fail Fast
Contents
As you probably know (I'm sure I mentioned it somewhere in this blog, not just in my CV), about a half a year ago, I developed a set of components to make our Linux Driver Verification toolset run in a cloud, i.e. on a set of dynamically added and removed virtual machines.
Being low on the amount of man-hours allocated to this task, I needed to make the development as fast as possible. Our toolset was, in fact a simple client-server architecture: it had a large task that split on several independent smaller tasks, and then collected their results. While we did have making our toolset distributed in mind (I even had a post sketching our small debate on how to create an parallelization-friendly architecture), the data exchange had been implemented long before the infrastructure for distributed computing. The data exchange was based on a strict layout of files in the working directory: clients expected the input data in specific places, and server was to ensure the proper files reside there. Then, the server read the output from the specific files the clients created.
Linux has a support for Filesystems in USErspace (FUSE). This means that a non-root user may install and mount a "virtual" file system that would map system calls to the files and directories to whatever user specifies, such as an access to an archive, or to a file on a remote machine.
One of such file systems, an SSH-FS, which mirrors a filesystem on a remote machine via a Secure Shell tunnel, was featured in my previous posts about open3.
In a cloud, a client and the server are located on separate machines. How do we perform the data exchange? The simplest way to do was to use a transparent network file system, such that the data access code is untouched. Indeed, clients just read files from a filesystem, and a combination of Linux filesystem tools maps the read() calls across the network to reads from a server machine.
To achieve this, I used a combination of SSHFS and UnionFS, both being userspace file systems (see sidenote). UnionFS was used to make client write to a local machine and read files from the remote server while thinking it's just one simple filesystem.
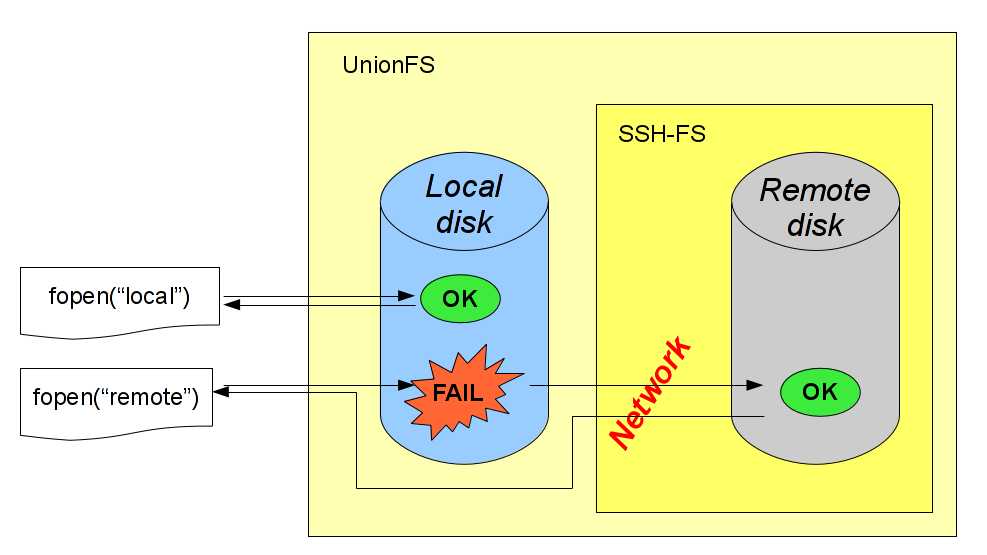
It seemed a nice solution because the files the client expected to find in a filesystem were seamlessly transferred via sshfs. Its caching capabilities ensured that the latency happened only when the file was located, and simple buffered reads on that file were cached in advance. Since we need to locate only a relatively small amount of files, but read a lot from them, the latency shouldn't have been crucial.
Have you already guessed where the problem is?..
The trouble: C preprocessing
And there was one simple task in the whole infrastructure, which never got much traction, but is now responsible for all the latency happening in the data exchange via network. Our toolset analyzed C source code, therefore, it needed to preprocess it. And the trouble was in that plain old C preprocessing; namely, its #include directives.
How do #includes in C preprocessor work? A compiler has a prioritized array of folders to look for headers in, the user specifies its own prioritized set of folders, and each #include <file.h> enumerates the array starting from the folder of highest priority, and looks up file.h in each of them, until it founds a match. Then it inserts the contents of the file found into the source code, and keeps preprocessing. What is the incompliancy with our assertions about the performance of our filesystem stack?
During C preprocessing, a very large number of file lookups will fail!
It's the crucial point of preprocessing; it's been working like this for decades, and we shouldn't touch it (we don't want it, too, as using C preprocessor as a third-party tool is much easier to deploy). This is an example of a completely legitimate motivation for issuing a lot of failed requests to something (to file system, in our case). And it works comparatively well locally: while preprocessing of one file on a local disc would take less than a second, the same task over the network requires ten, or more! What could we do with our filesystem setup to avoid such performance problems?
Nothing. The calls that are doomed to a failure on the UnionFS level will be routed over the network to fail on the server, causing insane amounts of latency. Even copying all the headers from the remote machine to the local one wouldn't help: the successes would be executed faster indeed, but the failures would make their way to the server, and cause latencies anyway.
***
What could be learned from this? When you're trying to design a system, you should pay a closer attention to failures. It's tempting to only optimize your architecture for a fast handling of successful requests, while failure of a request may be as much of importance!
Of course, this varies with your domain: for instance, a web authentication system would specifically slow down failures as a protection against brute-force attacks. In my case, however, I'll have to make a patch to SSH-FS (or, to UnionFS) for it to cache failed file lookups. And I did it! See my blog post that describes how I patched it
But when I'll design another piece of software in my career, and it will have to handle legitimate unsuccessful requests, I'll do my best to make it fail early and fail fast.
Could it be that line 171 of the time.pl sript
print STDERR "${id_str}MEM $timeinfo->{total}\n";
should actually be
print STDERR "${id_str}MEM $meminfo\n";
? Otherwise you print out the execution time instead of memory.