Counting Visits Efficiently with "Wide Caching"
Contents
One of the features of the web forum engine, a clone of which I develop in Ruby on Rails, is that it displays some site usage statistics.
There are two kins of statistics it displays. First, it tracks and shows how many times a particular message was read (i.e. clicked), tracking if a user doesn't self-click his or her message. Second, it shows the generic site usage activity, unique visitors, and page views in the top-right corner.
In this post I'll tell how I solved the problem of calculation the page view and visitors statistics. Impatient developers may jump directly to the solution section, while others are welcome to read about the path I walked from the most naïve activity tracking to the Wide Cache.
Naïve solution
The naïve solution was to store all site accesses in a table in the Application MySQL database. Each line in this table would represent one access to a site, keeping a user's hostname, and the access time. At each access, a corresponding line is inserted into the table. Then, if we are to display the information gathered, we run two simple db queries to get the pageview information (the time is the current time minus 10 minutes):
SELECT COUNT(distinct host) FROM `activities` ; SELECT COUNT(*) FROM `activities` WHERE (created_at < '2012-04-01 18:33:25');
The writes to and reads from the activities table happened at each request. This was achieved via a before_filter in the root controller which is usually named ApplicationController, as hinted in this StackOverflow question:
It spawned another process that handled all the activity business, and didn't prevent the main process from serving pages timely.
As you might expect, the performance measurements were disastrous: the application could serve only (four) requests per second, while with all activity stuff turned off the throughput was about 40 rps.
Storing the table in memcached
The reason why the naive solution was not working as expected was lack of throughput. At first, I thought that since we could defer the database writes, and perform them after the request was served, we wont have any problems. However, this only addressed one of the performance metrics, response time, while what solution lacked was throughput.
I also didn't want to introduce other technologies specifically for activity tracking. What I had at my disposal was memcached. Other components of my application used memcached to cache database reads and whole pages. We could, I thought, cache database writes with it as well.
Rails storage with memcached backend supports two operations. The first is to write something under a string key, perhaps with a limited lifetime. the second is to read from a specified storage entry if anything has been written to it before, and if its lifetime is not over yet. That's basically all.
We could try to use memcached to store the SQL table. itself. Indeed, that table may be viewed as an array of rows, so we could just read the table, append a row, and write the result back. However, for the sake of performance, memcached doesn't support any locking, so we can't just store the table described in the naive approach in a cache bucket. Two threads may read the array, then both append the next row, and both write, one row being discarded. This is a classical race condition. And my aim was to serve 30-40 requests per second, which means that race conditions that appear if this approach is used were inevitable.
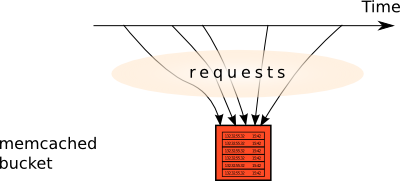
Besides, even if we could use locking (for instance, via Linux named locks (flocks)), it could even perform worse than the database, because it wouldn't be able to handle enough requests sequentially. We need a certain degree of concurrency here.
Wide caching
To mitigate the race conditions that happen during database writes, I used a technique I named "wide caching". I certainly reinvented the wheel here, but for the sake of clarity, I'll use this name in the rest of the post.
The race condition from the previous section could be mitigated by distributing the big "table" into smaller, independent tables stored in different memcached chunks. Writes to each of the chunks would not be protected by a mutex, so a race condition would be possible. We could try to mitigate it by using a round-robin chunk allocation, i.e. a new thread writes to the chunk next to the one allocated to the previous thread.

This solution, however, could be improved.
First, round-robin allocation requires a central, synchronized authority to return proper chunks. This brings the same level of technological complexity as a single bucket with a lock.
Second, round-robin doesn't guarantee the lack of race conditions either. A thread may stall long enough for the round-robin to make a whole "round", and to consider the chunk currently in process again. To avoid this, the allocator should be even more complex.
Third, let's realize that we may trade precision for speed. The result will not be absolutely accurate. People look at the site usage statistics out of curiosity, and the figures may not be precise. We'll try to make them fast first.
This all suggests a simple idea: get rid of the allocator! Just use a random bucket in each thread.

This will not prevent us from race conditions either, but it will make them predictable. If the allocation is completely random, we can carry out experiments, and extend their results in time being sure that they will be reproducible.
Decreasing effect of race conditions
The previous paragraph consisted of reasons and measures that addressed the amount of potential accesses to the same cache bucket within a period of time. What also matters is how long this cache access is. The shorter it is, the more writes to a hash bucket per second we are going to handle correctly.
Memcache request structure
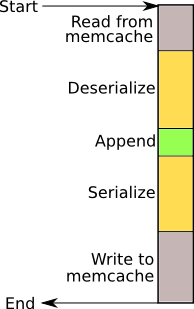
Rails provides a transient interface to various caches. The interface allows to store serialized Ruby structures in the cache. This picture shows the steps that happen during an update of a table in hash, the scale roughly representing the time each of the steps take.
A typical hash bucket access consists of these steps:
- reading raw data from cache;
- deserializing, converting to Ruby format from a character format (the opposite to serializing;
- appending a row to the deserialized table;
- serializing to the character format (the opposite to deserializing);
- writing raw data to the cache.
We can see that steps 1, 2, 4, and 5 depend on the amount of records in the array we store in the hash bucket. The more information we record, the more time they take, and when the data are large enough, the time becomes proportional to the size. And if we just store all the activity data in cache, the size of the arrays being (de)serialized only grows in time!
How could we decrease the size of buckets? The wide cache already decreases the expected size by a factor of width, could we do better?
It turns out we can. Activity is a time-based data. The older the data are, the less interesting they become. In our use-case, we were only interested in the data for the latest 10 minutes. Of course, the routine cleanup of tables that drops all records with old enough timestamps is not sufficient: the activity data for 10 minutes are large enough (with 50 rps, and 50 being the cache width, the mean size would be 600).
Time reminds us about another idea. Why do we load and then write the old data for the table? They don't change anyway! Since we're using a generic cache solution, and can't lurk into its read/write algorithm, we can't do it on a per-record basis (i.e. do not load the table, just append the record being inserted. What can we do instead?
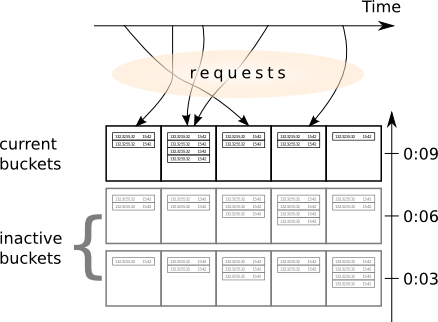
We may utilize another highly-accessible resource, which usage is however totally discouraged in building a reliable distributed algorithm. We have the clock that are easy and fast to access. The clock provides us with a natural discriminator: each, say, three seconds, abandon the old hash bucket, and start a new that will be responsible for storing the requests for the next three seconds. Given current time, we can always find the "layer" of the cache we should randomly select the bucket from.
Reading the data back
The discussion above was devoted to how to record the activity data. However, the data should be displayed in a timely manner. How timely? Let's consider that if the data are updated at least once per 30 seconds, it's good enough.
Then, each 30 seconds we should reconcile the activity data written into the memcached, and "compress" it to an easily readable format. Since I already had MySQL implementation before, I piggybacked on this, and merely inserted the activity information to the SQL table, so the reading procedures do not have change at all!
To get the statistics, we'll have to iterate all hash buckets the writing algorithm could fill, because gathering the ids of the buckets filled will require additional synchronization (additional writes), and, since the majority of them will be filled under high load, we'd better just collect them all. Theoretically, we should collect all the buckets that might have been filled during the last 10 minutes, the period we show the activity for. However, if we run the collecting algorithm each 30 seconds, we can only collect the data for the latest 30 seconds as well, since all the previous data should have already been collected.
We'll have another race condition here. A worker may get the current time, generate a hash bucket id X, and then stall for several seconds. During that stall, the writing worker collects the commits all the data to the MySQL table, including the piece stored in X. The first worker wakes up, and writes the visit information to X, from which it will never be read, so the request is lost.
To mitigate this race condition, we may collect and commit the data only from the layers that are deep enough. This won't help to avoid it completely, but will decrease its probability to the degree at which we can ignore it.
The final Wide Caching solution
If we assemble all of the above, we'll get the final solution that looks like this:
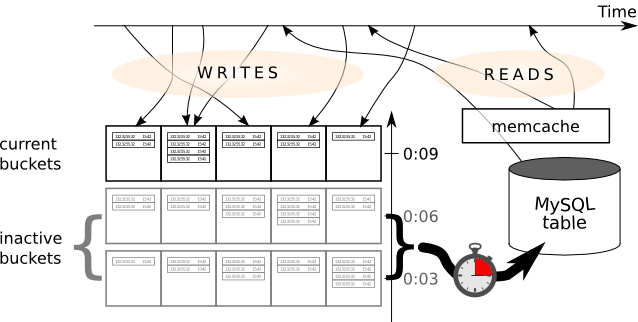
When a page request arrives, it asks for the current site usage statistics as one of the steps during the page printing. The statistic data are requested from the `activity` table in MySQL database, and are cached for a medium amount of time (30 seconds), because more frequent updates do not improve user experience.
After the page has been served, the request notifies the wide cache about the access to the site. First, it determines the "row" of the cache by rounding the current time in seconds since the Epoch down to the number divisible by three. Then, it determines the "column" by choosing a random number from 1 to 15. These numbers are appended; they form a unique identifier of a memcache entry. The website then reads the table from that entry, appends a row, and updates the same entry.
Dumping the collected accesses to the DB is performs like this. After notification, the request also checks if there is a live memcached entry with a special name, and a lifetime equal to 30 seconds. If there is such entry, it means that the information in the DB is obsolete, so the algorithm starts to commit the information into the MySQL DB.
While the information is being committed, there may appear other requests that would also check the lifetime of the memcached entry, and start the commit process. This is why the order, in which the memcached entries are being read is randomized, so that the amount of cases when the same information is committed twice is minimized.
Here's the code. It really looks much shorter than this post that describes it.
The latest version of the source code may be found here.
Experiments
I mentioned that the setup contains race conditions that will lead to losing some requests. With the cache width of 15, and bucket height of 3 seconds, the payload of 35 requests per second made the tracker lose 350 out of 6800 requests. This is approximately 5% of total number of requests, which is acceptable. Because we randomized request queries, we may conclude that 5%—given these figures for requests per seconds, cache width, and the equipment—will be an average visit loss factor.
Spawning
In previous sections, I claimed that spawn-ing threads using spawn Rails gem, and writing to the database in the spawned processes/threads is slow. Indeed, spawn reinitializes the connection in the spawned thread, and this is already a considerable burden on the server if several dozens of threads are spawned each second. Here are the experimental details (see bug #67 where I first posted them info):
| Method | Reqs. per sec. |
|---|---|
| No activity | 40.2 |
| With activity; no spawning | 27.4 |
| With activity and spawning | 13.0 |
| With wide cache | 36.7 |
This shows that (a) you should not use spawning for short requests, and (b) wide cache is really fast enough.
Background periodic job or per-request?
In the algorithm described above, activity data collection was started when a request arrives, and the application finds out that the currently cached activity stats are out of date. We were careful to make this case as painless as possible, but it has other implications that are not related to race conditions, and experiments show that the loss of throughput is acceptable if we don't try to spawn a thread for each this activity.
Surprisingly, this method starts performing badly when the site activity is low rather than high. On a low-activity site, we can't rely on requests coming each second. Rather, they may arrive even less frequently that activity cache times. So, to support the low-activity case, we have to collect the information for caches that might have been filled in the latest 10 minutes (the maximum value a visit information could still be relevant for), not 30 seconds (the lowest possible time since the previous data collection). Otherwise, if users arrive less frequently than 30 seconds, the engine would always show zero activity, which would make users visit the site even less.
This wouldn't be important, unless I used HAML template engine, which—and this is a known, sad bug—doesn't flush the page until the request is complete. Even putting the code to after_filter doesn't help. Experiments demonstrate that activity data reconciliation may take up to 1 second, so some requests will be served with an excessive 1-second delay, and when the rate of requests is low, this will constitute a considerable fraction of them. And I surely don't want my users to experience frequent delays during their infrequent visits.
Spawn instead of after_filter? We have already seen that spawn-ing will make our server choke at the other extreme, when the load is high.
Luckily, we have a solution that suits both cases equally well. It is to periodically invoke the activity data collection procedure, without tying it to requests. However, the periodic invocation of a task is not straightforward in Rails. I'll get back to it in another post.
Future work
The current implementation of the activity tracker is parametrized with cache attributes (cache lifetime, and width). However, this Wide Cache could be parametrized further, with the procedures that are executed, namely:
- Cache bucket updating
- Commit procedure
- Reading what we previously committed
I think that I'm going to need the same cache that doesn't always touch the database for the first kind of the activity, for visits of individual posts. This parametrization will help me to keep the code DRY, and to re-use the Wide Cache.
This will require refactoring of visits and hits to a single function that calls a lambda function passed in the constructor.
Other approaches
Parse apache/nginx/rails logs.
Indeed, the topmost web serving layer already collects the activity data: it carefully logs each visit, with the URL being visited, a user's IP address and user-agent. Instead of spending time on activity in a comparatively slow Rails application, we could use the logs of a "fast" web server.
I have seen production systems that display activity data based on parsing nginx logs, and it may be integrated into Rails in such a way that it doesn't look like a kludge. Perhaps, free log parsers are already available on github... but this solution just doesn't look cool enough to me.
Do no track activity
Does anyone care about the visits at all? Maybe we just shouldn't track them?
First, from my observation, everybody tries to stick a visit tracker into a website. A bigger activity also means that you're visiting something valuable. A Russian clone of the Facebook social network even used to display a fake registered user number counter at their homepage. Such fraud could only be justified by a huge benefit from displaying it, which means that the statistics is considered valuable by at least some very popular sites.
Second, in my case, there was an easier answer. I should reimplement everything the engine I'm trying to clone contains by politics-related reasons: unless I reimplement everything, and manage to keep the site fast at the same time, my approach to the development will be considered a failure.
Use a specialized activity tracking solution
Too late. I have already implemented my own. But if you want some activity data on your website, do not hesitate to use one. It is hard, see above.
Conclusion
In one of the discussions on the very forum I'm reimplementing, someone wondered, why the view count on Youtube is not update in realtime for popular videos. Having gotten through a series of trial-and-failure experiments with visit tracking, I realize that the developers of Youtube surely had their reasons. My activity information is also already delayed, while the traffic volume still insignificant compared to even a single Lady Gaga video.
It seems that during the development of this tracking I have reinvented a lot of wheels. This is how, I guess, the most primitive database and file systems caches look like. Their algorithms are, of course, more sophisticated, and are not built on top of the generic cache and serialization solutions, using their own, custom ones instead.
But as any other re-invention of a wheel, it was fun, and I surely got a lot of understanding about higher-load web serving while trying to optimize this component of the forum engine.