How Static Verification Tools Analyze Programs
Contents
One of my previous posts featured a plaque we got for scoring an achievement in the Competition on Software Verification'12. I promised to tell how the tool we improved analyzed programs to find bugs in them... without actually running them.
Please, note that most of what's described here was not devised by me. It was a state of art when I first started to study the field, and my contribution was kind of tiny—as usual when newbies do their (post)graduate research.
Program Verification is Impossible
I promised to tell you how we do it, but the thing is that... this is actually impossible. Not that I'm holding a secret vigilantly protected by the evil Russian Government, but it's just mathematically impossible. It's not just "hard", as in "NP-hard", but plain impossible. A proof of impossibility of a relevant problem, the halting problem, published in the famous Alan Turing's paper is acknowledged as one of the stepping stones at the beginning of Computer Science as a math discipline. Later it was found that halting is not an anly property you can't universally verify with a computer program: in fact, any nontrivial property can't be universally verified! This is known as Rice's theorem, and was known since 1953.
The undecidebility (one more term to denote the inability to build a program that solves a problem) of program verification only concerns Turing complete languages, i.e. the languages that are as powerful as Turing machine. Some languages can be correcly verified, such as a hypothetic language with no variables and no statements other than print (always terminates), or its extension with non-folded for...to and for downto Pascal-like loops, so that halting can be solved by comparing the numbers involved.
Most interesing real-world problems involve reasoning about constructively non-trivial languages though.
Absence of a program that can verify if any given program halts or bears some nontrivial property means that for any program that claims to be such a universal verifier, there exists a counterexample, a piece of source code that will confuse the self-proclaimed verifier or make it loop forever. But the very same verifier may provide useful results for a multitude of programs that at the same time. Considerable pieces of computer science and software engineering are devoted to studying, building, and putting such verifiers into production. A lot of program analysis, which is closely related to verification, happens in compilers, so you most likely unanimously encounter the results of this research on a daily basis.
In the next sections I'll explain one of the approaches to verifying programs, to which my graduate research was closely related.
Why Go Static?
So how would you verify that a program doesn't have certain bugs (say, never dereferences a NULL pointer ever) without having it run and take potentially harmful effect on customers and equipment?
If your initial idea was to try to interpret program in such an environment that its running wouldn't affect anything, that would not work. First, it hardly counts as "verifying a program without running" as it actually runs, but in isolation. Second, and more important is that the program may involve a user input. This may be an input from keyboard, from text file, or from network. How do you verify the program behavior if the way it behaves depends on what comex from external sources?
You could emulate the behavior of these external stimuli by writing some mock-ups (say, by reimplementing fread("%d",&x) as something that make x a zero), but this is effectively resorting back to testing. The whole idea of static verification—when the program is not run—is to extend the number of possible program execution scenarios beyond the those you can cherry-pick by testing. When you see a scientific paper on static verification techniques, it will surely list the possibility of checking all the possible scenarios as a justification of the increased resource consumption compared to testing in isolated environment—well, who tests in production anyway?
Of course, white-box static verification is not the only complicated testing technique. An interesting testing technology, UniTESK has been developed in ISPRAS, where I previously worked and studied. One of its features is that it can automatically adjust the tests generated to cover all possible disjuncts in if statements of a method's postcondition. This means that not only each condition branch should be covered, but each of the operands in a disjunction that forms each condition should be true during the test execution. The disjuncts we're talking about here are those in the postcondition, the system under test itself being a black box.
And a justification it is! It's not possible to enumerate all the possible inputs and stimuli, because the number of their combination is infinite even for simple programs. And if you omit some input pattern, who can guarantee that something wrong doesn't happen exactly when users behave like this? You surely know a lot of cases where seemingly "dumb" users unveil behavior no sane person could ever predict when writing tests to software! In fact, any black-box test generation technique is inherently incomprehensive, and can't cover all cases possible. Static analysis "opens" the black box, sees and works with what is inside it, and it is more complicated than writing tests and measuring coverage.
Another case that is better left to automated comprehensive tests is security-related operations. Security-related bugs, such as buffer overflows, are hard to test. Ample testers for such bugs are called "hackers", and they are rare, expensive, and still are not reliable, and may miss something. One would like to ensure that no matter how malicious or damaged input from the network is, no matter what mischief the user clicking on the screen has in their mind, the program doesn't crash or expose certain security breach patters such as the aforementioned buffer overflow. Static verification is used in some very big companies, for instance, to make sure that a specific security bug occurs nowhere else in the system, so that the updated system would only laugh at the inspiration the descriptions of the problem might have caused.
Thus, static verification that reads the source code and may prove that the system is not exposed to certain kind of bugs and security violation patterns is also useful. Static verification is the only way to vouch for infinite number of inputs that they do not expose any bugs in the program. It allows us to consider all possible inputs at the same time as if a randomly-spanking monkey is operating the console rather than a sentient human being.

But, more on that later. It's still not clear how the multitude of possible patterns of security breaches can be studied generically. Do we have to study pointer dereferences, buffer overflows, memory allocation errors etc separately? Some tools try to, but there are fundamental approaches that address this problem of excessive diversity.
Reduction to Reachability
Reachability problem can be formulated like this. Given a program "state," find out if this "state" is reachable for some program execution. If program allows external input, this involves checking if there exists an input such that a program would reach the target state upon execution. We'll explain what the "state" is later.
This problem is as hard as the halting problem because the latter may be reduced to the former. If we know how to solve reachability, we know how to solve halting by checking if the exit state is reachable. It's not just very hard, as an NP-complete problem, it's just impossible to solve in a generic manner for all programs, as pointed out at the beginning of the post.
Reachability is important because a number of programming problems and bugs may be exposed as reaching "error state", a specific program line that gets executed when something undesirable happens. This could be a code that's responsible for printing "Segmentation fault", and checking reachability of this would give us a notion whether NULL pointer is dereferenced anywhere.
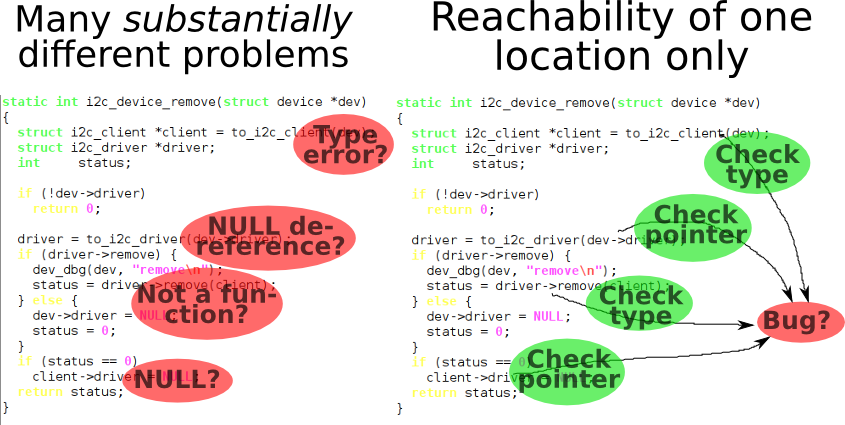
As this code is OS-specific, the programs being checked often are prepared to verification by inserting this code explicitely. So the code a = r/p, for instance, would decome if (p == 0) ERROR(); x = r/p;, where ERROR() terminates a program with error. Well, it doesn't actually have to terminate anything because we're not going to run this program as the verification is "static". Its purpose is to mark a specific place in program as undesirable. The process is sometimes called instrumentation. A special tool performs this operation; we developed a GCC-4.6-based one in ISPRAS during our Linux Driver Verification project.
Modeling Nondeterminism
So, how do we model the fread("%d") function? Let's get back to the original goal, which is to check if a program is free from runtime crashes and vulnerabilities. Thus, we can't assume anything on the user input, because a hacker may be operating the keyboard trying to enter a number specifically. What can we do then?
Static analysis techniques allow us to assume that the user just enters something—and soundly act upon that. The integer read may bear any value, literally! How does it play out then? The thing is that the integer entered is read once, and its value doesn't change arbitrarily after this, unless directly assigned to it, or to a pointer to its memory location. Then, such value is transferred to other variables, which make conditions over these variables either true or false, which affect how subsequent conditions are evaluated, and what code is executed. The ties that exist between values during the program execution are exposed, and it becomes possible to rule out some code as unreachable.
Note that if all ERROR() functions share the body, we may treat the body itself as an error location. This means, that any number of "error" locations is equivalent to one "error" location, so we sometimes go plural or singular for the sake of a better narrative.
We're lucky if we detect that all the ERROR() function calls are unreachable, which means that there's no bug. In other words, while we don't know the value of x, we know that any concrete value of x predetermines how the program executes from now on, until one more nondetermined variable is read from somewhere. Let's see on a simple example.
This uses a more simple model of reading an integer (to avoid discussion on pointer aliasing), which is read_int() function that returns an integer the user has entered. So, let's assume that it may return any integer. Can we still prove that a division by zero never happens, and the program never crashes at that statement? Sure. Whatever user returns, we can't get past the while loop until x is greater than zero. We may loop forever, or exit after several iterations, but if we're out of the loop, the x is surely equal to one or greater, i.e. x >= 1
Now, the crash happens if x == 0. But x == 0 and x >= 1 can't both be true. Moreover, whether it can be true or not, can be checked automatically with specialized software that is largely presented both in open-source and in proprietary forms. This demonstrates that we don't need to know exact value of each variable to determine if a program reaches an error location.
So, to model all possible ways the program works (including those ways that depend on the external, unknown input,) and to determine if any of these ways has a bug (i.e. ends in an "error" or a "crash" location) is the purpose of reachability solver's work. Let's see how is it possible.
Feasibility of Program Paths
The "equation" we used in the previous section to demonstrate how we could model nondeterminism is actually a powerful technique. It is generic enough to work in both nondeterministic and deterministic cases, and no distinction between them is even required! Each program where a certain line is marked as "error location" contains a number of "paths", sequences of statements that end in an error location, but for which it is not yet known if the program could actually follow this path. An example of such path is the above assignment x to zero, and having a check if it's greater than one passed. We've already shown that it's not feasible if we look closer at he path equation rather than just at program structure.
This usually requires some conversion. For instance, if we convert a fairly common assignment i=i+1 to an equation component i==i+1, it would render any path infeasible, since this can never be true for real numbers. In such cases, i and all its further occurrences are is renamed after each assignment (this is called Static Single Assignment (SSA) form).
Checking such equations requires using of advanced software such as SAT-solvers, theorem provers or customized built-in add-ons or reimplementations of them. These tasks are NP-complete problems, so the size of programs being verified matters. Modern software doesn't struggle with such "path equations" for programs as large as thousands to hundreds thousands of lines of code. Program size is not the only factor though. The size also depends on how precisely the formula describes the state of the variables and of the memory as a whole. For instance, pointer alias analysis makes the equation bigger for a given program.
Analyzing Program as a Whole
So far we've examined how tools like BLAST reason about individual paths. How does it turn into the whole-program analysis? The problem here is that, in any program that contains a loop, there may be an infinite amount of paths to analyze. Analyzing them one-by-one will never lead us to final solution provided we only check each single path. We need to somehow analyze paths in large quantities.
One of the possible patterns to perform such analysis is to split all paths into classes, such that we need to analyze one path, and somehow understand that the result of this analysis applies to a whole class of other paths, potentially infinite. This approach is applicable to many different tasks, and is not limited to the problem we are discussing.
At this point we notice that, wherever the program counter is, the behavior of program is completely predetermined by the values of all variables given the subsequent user input is also predetermined. For example, assume that at line, say, 15, in the middle of the loop, the values of all variables, and of the all readable memory cells are the same on the 2nd and the 3rd iterations of the loop. Immediately follows that the paths that "start" at each of these locations (given the equivalence of the memory) have a one-to-one match between these two "classes". Getting back to the original problem, if we prove that no path that only iterates two times has a bug on it, then the paths where the loop iterates three times or more also don't have bugs on them. This is how we can decrease the amounts of paths to analyze from infinity to several.
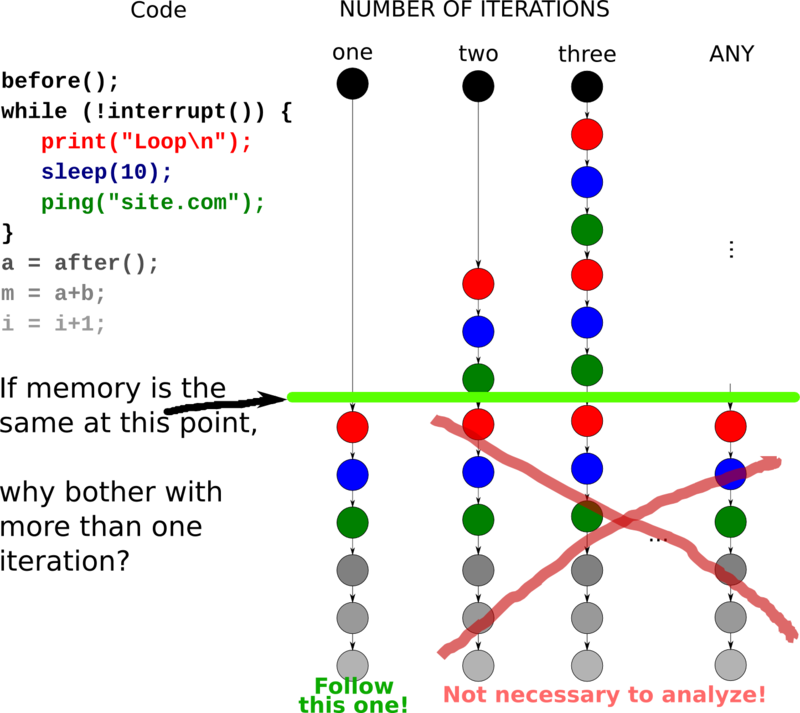
However, the loops where memory states are equal on subsequent iterations are rare. Such loops are either infinite (which is good for our analysis, since we don't encounter a crash if we loop forever doing nothing :-), or contain of user input only. The loop in the division by zero program does satisfy the condition, but what if it looked like this:
This way, attempt counter on each loop iteration is different. How do we tackle this one?
From State of the Whole Memory to Regions
While the memory state of the program in question is different at each loop iteration, it really does not matter. Indeed, whether the x equals zero does not depend on the attempt number. If user enters zero on second attempt, he or she could have entered it on the very first attempt, and our analysis algorithm accounts for that, as shown above in the "Modeling Nondeterminism" section. So all paths with two or more loop iterations are equivalent to the path with one iteration only--if we consider only the relevant memory cells that really affect whether the bug appears. How do we detect these memory cells?
Let's get back to the analysis of a single path. The path that only contains one loop iteration is converted to this equation:
attempt_old == 1, and attempt = attempt_old + 1, and x >= 1, and x == 0
The SAT solver analyzes this, and says that "this equation has no solution." But what if we ask "why?" Why does this equation have no solution? "Well," we could answer, "because x can't be no less than one and equal to zero at the same time!" What is important in this answer is that it never mentions attempt variable. So we may discard this variable from the list of "important" variables, and compare paths with 1 and more loop iterations based on the value of x only, and from this point of view they are all equivalent.
Of course, if the value of attempt is later discovered as relevant (i.e. someone tries to divide by it), the equivalence of paths may be reconsidered. But sooner or later, (if we're lucky: remember that the problem is not solvable universally!) we run out of relevant variables.
Note that we eluded the question of how we realize that x is relevant, and attempt is not automatically, without asking any human (that's the whole point of automated large-scale program analysis). First, we can try to ask the SAT solver. Such solvers do not just run on magic, they execute established algorithms, that can sometimes give us notions why the answer is such and such. Second, we can try to play with the equation a bit by trying to remove the parts related to attempt variable and checking if the equation is still not solvable. Third, we can use the mathematical concept that formalizes the "why?" question, such as "Craig interpolation".
In most cases, such algorithms not only tell what variables are relevant, but also give us hints about when they are relevant (say, Craig interpolation may tell us that it's enough to check if x is greater than zero rather than see its actual value. This also solves another problem: tracking exact values of variables is suboptimal. If it is important that x is greater than 0, then every single positive integer value of x is equivalent, which would not be the case if we separated paths based on the exact value of x.
Such "conditions" that constrain the memory values are composed into "memory regions", (potentially infinite) sets of memory cell values that can be used instead of the previous execution history. Indeed, at each line we need to either know the complete history, what lines have been executed by now, or know the current memory state—or at least some constraints on it. We don't need to know both to predict how the program will behave after we continue execution.
The overall algorithm
To sum up the previous sections, here's how the anti-bug program analysis algorithm works:- First, consider that memory is totally irrelevant.
- Try to find some path given that any memory cell may hold any value at any time (even if variables change magically between they're written to and read from) that ends up in the ERROR location
- If there's no such path, there's no bug!
- If there is such a path, convert it into the path equation, and try to solve it.
- If the equation has a solution, then the bug is here.
- Otherwise, ask the solver or other advanced tools "why" is the equation unsolvable (more generic question is, "why is this path infeasible?").
- Reevaluate the paths in the program, not blindly this time, but rather tracking how the memory regions we get on the previous step affect the equivalence of the paths (we leave other variables change magically though). Only follow one path among those equivalent to each other.
- Is there any path that ends up in the ERROR location under the new circumstances? Go to 3 or 4.
The algorithm is laid out this way to provide the explanation how it works. An explanation why it is correct, as well as the most convenient form to advance the state of art, requires us to think from the last poit to the first. One should first envision a novel representation of the multitude of program paths, and then devise how to compute it efficiently.
If we're lucky, the algorithm finishes. If we're even more lucky, the algorithm finishes in a sane amount of time. Depending on the task, the "sane" ranges from five minutes to several days. In LDV, we considered it unacceptable for an individual driver to take more than 15 minutes to get verified against a single bug, but Linux kernel contained 4500 of them. In a less massive setting the time constraint can be increased; some mid 2000-s studies considered three days for exhaustive verification of 2500-LOC programs.
This algorithm pattern is called CounterExample Guided Abstraction Refinement (CEGAR). It was devised less than 15 years ago. It was based on the 45-years-ago advancement by Cousot&Cousot that were first to propose to "abstract away" from the actual variable values (what we did when we allowed variables to change magically unless specifically tracked), and iteratively "refine" the "abstraction" by tracking more and more properties. This is not new stuff, but is not old either.
We omitted certain points in tese algorithms. For instance, even the early framework algorithms, even unimplemented, envisioned tracking whether classes "fold" into each other rather than whether they're equivalent only, leaving the exact implementation behind the "lattice" abstraction of program states. Second, the way how "memory regions" are affected by statements is also a complex theory, and it's surprisingly easy to create an algorithm that piggybacks on formula equation building and SAT solving, see this paper for details if you're curious. The paper also outlines a framework approach on alias analysis and memory modeling.
Common Limitations
The common limitations of this algorithm (compared to other static analysis algorithms) is that it relies on a complex equation solving and proving tools that are only well-defined when working with numbers and not very complicated formulae. Even C programs, however, are fairly complex, and consist of complicated concepts such as arrays, pointers, structures, bit shifts, bounded integers when adding two positive integers sometimes makes the result negative. Converting them to good ol' numbers introduces complications. For instance, it's increasingly more hard to answer the "why?" question as you introduce operators beyond addition, subtraction and multiplication: bit shifts, modulo calculations, square roots make it nearly impossible. The fact that pointer may point anywhere—or, at least, to several locations—makes the number of variants of program behavior explode. And if it's a pointer to function, things get ever worse.
Still, the approach works. We found several dozens of kernel bugs in Linux Kernel device drivers—and keep in mind that we did not have the actual devices! Slowly, scientists make it less fragile, more reliable, and some day it will also commercialize to products based on different static analysis approaches, such as Klokwork and Coverity.
Meanwhile, you may try to use such research-space tools as BLAST or CPAchecker, as well as check other SV-COMP participants.
Conclusion
So this is one of the approaches to program verification. There are others, but you may always notice the same pattern in them: abstract away from the concrete program, discard everything that seems impossible, and hope that you discard all bugs and bugs only. However magical it seems, it does work. If you run Windows, your PC is actually executing millilons of lines of statically verified tools. Microsoft has been carrying a lot of really interesting and relevant research and development in this area for the past decade, as I learned at one of the conferences hosted by MS Research.
I wanted to write this article for years, but never managed to find time for this. This was fun even though I stopped active participation in static analysis research or development. I hope I outlined one of the approaches to program verifications so that a non-scientist could understand. If not, mail me or post a comment, and I'll improve the article. Don't hesitate to ask about something in comments, and I'll try to answer your questions—or at least to direct you somewhere.