Four years later, GNU Make 3.82 is released!
Gnu Make is not one of those products, website of which you frequently check for updates. One of the reasons is it's leisurely development pace: version 3.80 was released in 2002, 3.81—in 2006, and 3.82—in 2010. So each new release is breaking news.
Why so conservative?
Why's that? Well, I can't know for sure, but let me introduce some facts about the product.
First, Make is actually a profound tool. It contains a lot of very basic features, which makes nearly every build scenario you can imagine plausible to be implemented as a Makefile. Make's even Turing-complete. I think that this made the majority of people who develop Make think, that Make is already a perfect tool to do its job.
And then we see CMake, which is something that compiles into Make, just like Make was an assembly language of sorts...
What Make it actually lacks is a "standard library", something that would make using Make more convenient to writing complex stuff. If not that, there's nearly nothing to add to Make. And nearly nothing is added indeed.
But is it really conservativeness? What could characterize a conservative design? Perhaps a pursuit for stability and compatibility among releases?
However, this doesn't seem the case either. Some new changes (I'll comment on them later) introduce backward incompatibility—i.e. some old makefiles wouldn't be processed by Make. Some of them broke the build of one of the basic component of GNU/Linux system, Glibc (C runtime library)! This Glibc bug was filed only five days after the release of Make 3.82. Not before. This means that this backward-incompatible change, while forward-compatible, was not addressed, or checked, or noted, by anybody (and not by Make maintainers in the first place)! Is this called conservative?
An only conclusion I can make is that Make has reached all its capabilities. It's maintained, you know, not by the most stupid people in the world. And even if they can't foster its progress then who could? Perhaps, no one, and that's the point?
So what's new?
But alright, let's observe the changes GNU Make 3.82 brings us. If you go to the official site of GNU Make, it will kindly redirect you to the NEWS file, to get which you should download and unpack the release. But I'll release you from this burden, and quote the file here. Fully. Look:
Version 3.82
A complete list of bugs fixed in this version is available here:
http://sv.gnu.org/bugs/index.php?group=make&report_id=111&fix_release_id=104&set=custom
* Compiling GNU make now requires a conforming ISO C 1989 compiler and
standard runtime library.
* WARNING: Future backward-incompatibility!
Wildcards are not documented as returning sorted values, but up to and
including this release the results have been sorted and some makefiles are
apparently depending on that. In the next release of GNU make, for
performance reasons, we may remove that sorting. If your makefiles
require sorted results from wildcard expansions, use the $(sort ...)
function to request it explicitly.
* WARNING: Backward-incompatibility!
The POSIX standard for make was changed in the 2008 version in a
fundamentally incompatible way: make is required to invoke the shell as if
the '-e' flag were provided. Because this would break many makefiles that
have been written to conform to the original text of the standard, the
default behavior of GNU make remains to invoke the shell with simply '-c'.
However, any makefile specifying the .POSIX special target will follow the
new POSIX standard and pass '-e' to the shell. See also .SHELLFLAGS
below.
* WARNING: Backward-incompatibility!
The '$?' variable now contains all prerequisites that caused the target to
be considered out of date, even if they do not exist (previously only
existing targets were provided in $?).
* WARNING: Backward-incompatibility!
As a result of parser enhancements, three backward-compatibility issues
exist: first, a prerequisite containing an "=" cannot be escaped with a
backslash any longer. You must create a variable containing an "=" and
use that variable in the prerequisite. Second, variable names can no
longer contain whitespace, unless you put the whitespace in a variable and
use the variable. Third, in previous versions of make it was sometimes
not flagged as an error for explicit and pattern targets to appear in the
same rule. Now this is always reported as an error.
* WARNING: Backward-incompatibility!
The pattern-specific variables and pattern rules are now applied in the
shortest stem first order instead of the definition order (variables
and rules with the same stem length are still applied in the definition
order). This produces the usually-desired behavior where more specific
patterns are preferred. To detect this feature search for 'shortest-stem'
in the .FEATURES special variable.
* WARNING: Backward-incompatibility!
The library search behavior has changed to be compatible with the standard
linker behavior. Prior to this version for prerequisites specified using
the -lfoo syntax make first searched for libfoo.so in the current
directory, vpath directories, and system directories. If that didn't yield
a match, make then searched for libfoo.a in these directories. Starting
with this version make searches first for libfoo.so and then for libfoo.a
in each of these directories in order.
* New command line option: --eval=STRING causes STRING to be evaluated as
makefile syntax (akin to using the $(eval ...) function). The evaluation
is performed after all default rules and variables are defined, but before
any makefiles are read.
* New special variable: .RECIPEPREFIX allows you to reset the recipe
introduction character from the default (TAB) to something else. The
first character of this variable value is the new recipe introduction
character. If the variable is set to the empty string, TAB is used again.
It can be set and reset at will; recipes will use the value active when
they were first parsed. To detect this feature check the value of
$(.RECIPEPREFIX).
* New special variable: .SHELLFLAGS allows you to change the options passed
to the shell when it invokes recipes. By default the value will be "-c"
(or "-ec" if .POSIX is set).
* New special target: .ONESHELL instructs make to invoke a single instance
of the shell and provide it with the entire recipe, regardless of how many
lines it contains. As a special feature to allow more straightforward
conversion of makefiles to use .ONESHELL, any recipe line control
characters ('@', '+', or '-') will be removed from the second and
subsequent recipe lines. This happens _only_ if the SHELL value is deemed
to be a standard POSIX-style shell. If not, then no interior line control
characters are removed (as they may be part of the scripting language used
with the alternate SHELL).
* New variable modifier 'private': prefixing a variable assignment with the
modifier 'private' suppresses inheritance of that variable by
prerequisites. This is most useful for target- and pattern-specific
variables.
* New make directive: 'undefine' allows you to undefine a variable so that
it appears as if it was never set. Both $(flavor) and $(origin) functions
will return 'undefined' for such a variable. To detect this feature search
for 'undefine' in the .FEATURES special variable.
* The parser for variable assignments has been enhanced to allow multiple
modifiers ('export', 'override', 'private') on the same line as variables,
including define/endef variables, and in any order. Also, it is possible
to create variables and targets named as these modifiers.
* The 'define' make directive now allows a variable assignment operator
after the variable name, to allow for simple, conditional, or appending
multi-line variable assignment.
Oh... My... God. Four years we've been waiting for this??? Three changes a year??
But let's observe the most important changes.
A lot of backward incompatibilities
Gentoo is a Linux distribution. I use it on my home machine, and find it highly convenient for a Linux used who likes to see how its system works. The pleasure of having such a system is of the same kind as watching clock with a transparent dial ticking, or keeping your PC without a cover.
One of its peculiarities is that by default every software is builtat the user's site. Package manager downloads sources and invokes ./configure; make; make install or whatever is relevant for the package. Since most of the Linux software uses Make to build, incompatible changes in Make's behavior is painful for such a system. That's why I refer to Gentoo bugzilla as to a good reference to bugs introduced by these changes.
By the way, you can get Gentoo at its homepage.
GNU naming convention is betrayed, a +1 to the minor version "81" breaks backwards compatibility. One issue with Glibc was noted above. Is there more? Sure. Here's a Gentoo bug that comprises all 3.82 regressions. Currently there's 40 breakages, and the list will most likely grow.
And if this change wasn't for nothing, I'd even understand this. Unfortunately... well, read along.
Shortest-stem makes Make more declarative!
* WARNING: Backward-incompatibility! The pattern-specific variables and pattern rules are now applied in the shortest stem first order instead of the definition order ...
You can define a "generic" rule, and then declare "amendments" to it by specifying, for example, prefixes to the filename, or the folders your target should be in. Now you can do it in arbitrary order, which makes the language more declarative. A good improvement, but, unfortunately, it really introduces nothing what couldn't be done before.
Linking change behavior
* WARNING: Backward-incompatibility! The library search behavior has changed to be compatible with the standard linker behavior. ...
That's the kind of change that contributes to "standard library" behavior: more flexibility with basically the same computational model. I could cheer upon this...if I used it at least once.
You can use something else instead of TABs
* New special variable: .RECIPEPREFIX allows you to reset the recipe introduction character from the default (TAB) to something else. ...
First, too late: Make is already notorious for its stupid tabs. Second, what other single character but tab could be used for this purpose? That's not even a regexp!
Of course, you can specify plain space character as this prefix. Then if your lines start with several spaces, the first would be recognized as prefix, and the rest would be ignored by the shell Make invokes. But then TABs won't work... So I doubt that this option would be used at all.
One shell for the whole rule
* New special target: .ONESHELL instructs make to invoke a single instance of the shell and provide it with the entire recipe, regardless of how many lines it contains. ...
First I thought, at last! I'm tired of writing multiline rules with these \ characters at the ends of the lines (that's especially painful if you have loops or conditionals inside the shell commands). However, I noticed that this is a global setting. So you can't just turn it on for certain rules; if you gonna turn it on, you have to write the whole makefile with these &&-s shell operators to mimic old behavior.
The rest
The rest is syntactical sugar and attempts to comply with the standards that evolve faster—and I actually couldn't imagine anything what evolved slower than standards—until this release, of course.
Conclusion
So the new release of Make is just a fucking disappointment. Yes, we certainly need something new, everyone says that (here's a link to deleted Tuomov's rant about Make, for example; thanks to QDiesel for that). More precisely, we have been needing it for several years. And I hope that in my search for the declarative language, I'll find something that could supersede this obsolete Make tool.


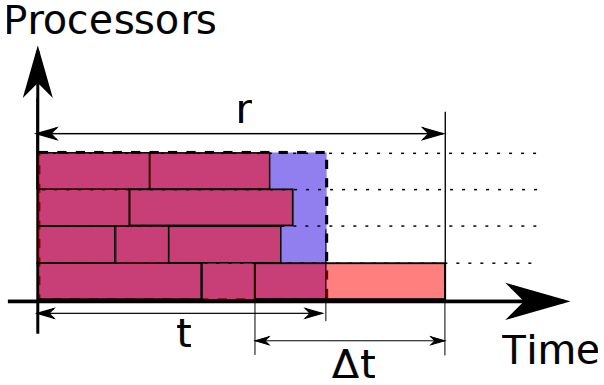

How's the search two+ years later?
You're right, you're not really clear what you want, but I love this area.
Here are some things you don't specify:
Pattern match?
How do you want to identify the things you want done? Can you produce some task description object and give it a simple ID? Is the description something you could hash? Does it need to include wildcards? Is it a predicate calculus expression with unification and maybe even ands and ors of subexpressions?
Persistent results?
Are the tasks going to produce data that can be reused by multiple further tasks, or are they "eaten" by the task that asked for them?
Modifying dependencies???
Are you sure you know what declarative means? :-) If so, how can the dependencies of a task change? In particular, how can they change without invalidating what's already been done with the graph? Are you just talking about something simple, like an OR, where finishing one task makes others unnecessary (at least for that OR)? Or a piece of code that, once it gets run, may change its mind about what subtasks it needs done?
Concurrency
How much control over allocation of tasks to processors? Do you want the control and coordination to be distributed or centralized?
Those are just points that struck me as important to nail down.
One idea is just to set up a module to make dynamic programming (or caching) easier in whatever language. Then the language for goals is just to call the function that computes the result you want. I know there's a simple module like that in the Python Package Index. I don't mean that caching is all you need, but that using a function interface to each task-type lets you start with a single-threaded program and incrementally add caching, threading, fine-grained scheduling, etc..
The Linda "coordination language" is a language with requests and triggers based on pattern-matches to assertions in a database. Very clean, and it interfaces to multiple languages. In contrast you could look at the CONNIVER manual for more complex and hairy ideas.
There seem to be many dataflow languages. Looks like some research would be needed to find out which ones might be useful to you.
There is a make system called SCons that is written in Python and is extensible to new target types. Its way of expressing dependencies and actions is somewhat different from make's.
You can steal my tiny, Python, single-threaded clone of make, myke. It's a little messy but it's so small you can turn it into your kind of mess.
There is Flat Concurrent Prolog. What's "flat" about it is that it's designed to give you control over the parallelism, within the Prolog paradigm, rather than spawning an arbitrary tree of processes on an ordinary Prolog program. Here's one free implementation.
Here is a link to some old discussions of FCP vs. Linda vs. the E language, a distributed object-oriented language.