Wikipedia used to do a pretty bad job at explaining the theoretical foundations behing the different
consistency models of multithreaded/distributed systems. Especially cryptic was the definition of
"quiescent consistency", which I try to explan further in this post. Just take a look at the articles, and see how inconsistent the consistency model descriptions are. I'll try to get them together.
What is a Consistency Model?
When one describes how a distributed system behaves, one typically mentions a "consistency model". This
"model" describes the difference in behavior between a system in a single-threaded operation and a
multi-threaded or a multi-machine operation of a system.
Assume that you're implementing a data structure (a set, for instance; say, you can add/remove elements,
and check for presence). The specification (model) for its behavior usually implies that the operations are performed sequentially. For instance, a set indicates a presence of an element if ant only if it was added before the presence check, and not removed after that. The terms "before" and "after" imply that there is an order in operations over that structure. While it is straightforward to know the order of operations in a single thread, it gets unclear if there are several threads or machines:
- Calls may overlap. If two threads call methods on the same structure at approximately the same time, the calls may overlap because they don't happen simultaneously in real world. In what order the calls took effect is not clear, however, because thread scheduling or network connection introduces arbitrary delays in processing.
- Calls may not take effect immediately. When a method call returns, it is sometimes not clear when
the operation actually "takes effect." By adjusting what "taking effect" means, the programmer may increase
the speed of some operations at the expense of their immediacy or strictness guarantees. For example,
a stack data structure might fail to preserve the order of the elements inserted in order to make the
insertions faster. This might make sense because the "ordering" of events observed in different parts of a
distributed system is not that well-defined to begin with. I talked about why this is natural in my other post "Relativity of Simultaneity in
Distributed Computing".
Object-Oriented Model and Executions
A consistency model usually assumes Object-Oriented approach to describing a system. Assume that we have
something (say, a set), and its internal state can be observed and altered only through a specific set
of methods (say, add(elem), remove(elem), and
bool in(elem)). The OO approach assumes that internal state is concealed or
unknown, so we do not define consistency models in terms of object's state. Instead, we place
restrictions on the values these methods may return based on when other methods were called in
different threads or machines.
In practice, method calls don't happen instantly, and the model acknowledge this. The methods called, with
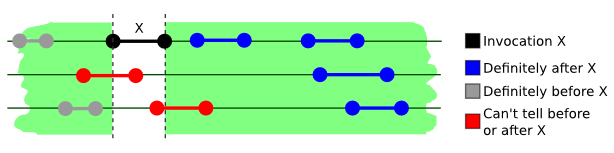
start and finish times, their arguments, and their return values is referred to as an execution. An
execution is usually depicted as intervals plotted onto lines. The parallel horizontal lines represent the
simultaneous passing of common, global time in different threads (ignoring for now, if this concept of global
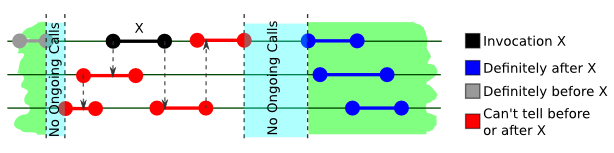
passing of time is valid). The intervals are the method calls, their beginning corresponding to the time the method was called and the end when the method returned. The call arguments and the return values as well as the method and object name are usually written near the method call. Here's a sample execution of a set object:

We will omit the actual call values further because consistency models do not operate in terms of actual arguments and values, but rather try to "map" concurrent executions to sequential ones. In our further diagrams we will also assume that all methods are called against the same object.
Since consistency model imposes restrictions on an execution, the latter may match or not match a consistency model. A data structure adheres to a consistency model iff every execution over its methods we may observe adheres to it. That's what's hidden behind such phrases as "sequentially consistent stack".
No Consistency
The most important consistency "model", is, of course, no consistency. Nothing is guaranteed. The methods called on the object may observe anything. We may add two different elements to an empty set, and observe that the size of set is three, and none of these elements is what we added.
All other consistency models are opposite to the No Consistency in the following sense. They all assume that the method calls may be re-arranged in a single-threaded sequence that is correct with respect to the object's specification. Let's call it arranged correctly in the rest of the post. For example, a set of pets that adheres to any consistency model described below can't tell us that it contains a cow, if only dogs were added to it.
"Multithreading" Consistency Models
What I discovered is that consistency models are divided into two categories: that lean to multithreading (shared memory multiprocessor systems), and to "multi-machine" (distributed systems). I find the former category more formal and mathematical; these models can be used to describe behavior precise enough to allow math-level, rock-solid reasoning about system properties. Some "distributed" consistency models are less precise in their definition, but are widely mentioned in documentation and description, and do allow users to make informed decisions.
Let's start with the "multithreading" ones.
Strong Consistency aka Linearizability
This is the most important consistency model to understand.
An execution is strongly consistent (linearizable) if the method calls can be correctly arranged
in a sequence that retains the order of calls that do not overlap in time no matter which thread calls them. (See "No Consistency" section for definition of "correctly arranged").
In other words, if two calls overlap, then they may "take effect" in any order, but if a call returns, then you may be sure it already worked.
A more anecdotal definition is "before the method returns, it completely takes effect consistently with other threads." This is also usually called "thread safety" unless more precise definition of consistency model is specified. This is quite a stringent restriction, especially for distributed systems, where threads run on different machines.
While it's unclear if the method calls marked in red happen before or after X, an important property must
also hold.
There must exist a sequence of calls such that they all make sense as if they were called from
one thread, while still satisfying the ordering constraint described above holds.
Two linearizable executions combined also form a linearizable execution. This is an important property, since it allows us to combine linearizable components to get strongly consistent systems. This is not true for other models, for instance....
Sequential Consistency
An execution is sequentially consistent if the method calls can be correctly arranged in a
sequence that retains the order of method calls within each thread.
The calls in different threads can be re-arranged arbitrarily, regardless of when they start and when they
end in relation to other calls.
An example of a sequentially consistent system is a naive notion of RAM in multi-core processor. When different threads read from the memory, they actually read from a cache or a register, which is synchronized with a common RAM at writes. While values read and written on different cores may not be immediately synchronized (cores may diverge in the notion of what value a cell contains), the values read and written on the same core are always consistent with each other. This is naive, though: even this guarantee is relaxed by modern compilers, and accesses to different variables within one thread can be reordered (as far as I recall, ARM platforms are guilty of this).
You might notice that the definition of sequential consistency does not directly prevents methods to return values from the future (i.e. to read what will be written later in a different thread). Yet I claim that RAM is sequentially consistent; how's that? The thing is that each execution should be sequentially consistent. If read and write do not overlap, and write follows the read, we may just stop the program between them. Since each execution should be consistent, the value read should be written before in some thread. Therefore, this "future prediction" is not possible in consistent data structures (not only those that are "sequentially" consistent) even that the definition doesn't directly prevent it.
However, if we combine two sequentially consistent executions, the result won't be sequentially consistent. But there is another model, weaker than linearizability, that makes it possible.
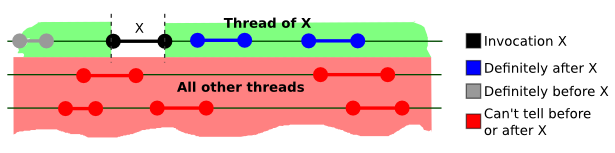
Quiescent Consistency
An execution is quiescently consistent if the method calls can be correctly arranged in a
sequence that retains the order of the calls separated by quiescence (a period of time when no
method is running in any thread).
This consistency condition is stronger than sequential consistency, but is still not strong enough to be
widely adopted as a discriminator. Implementations exist, e.g. see my other post for a
more in-depth example of a quiescently consistent stack. The model is mostly used is to
attain a higher degree of concurrency than linearizable components allow.
Quiescent consistency is rarely employed in production systems. Here's an example of how one can implement
a quiescently consistent system: assume that all writes are cached, and the cache is flushed to a persistent
storage when there are no ongoing writes (or after it reaches certain size). More specialized data
structures that are quiescently consistent exist.
However, many high-load distributed systems are almost never quiescent. A typical distributed web
service
may consist of hundreds of caches, frontends, and backend instances. If the service is really high-load (say,
serves order of millions of requests per seconds), no component is quiescent ever. Systems that rely
on quiescence to work (e.g. written in garbage-collected languages) have to "trigger quiescence" (this happens
when some Java virtual machines trigger "heap compaction"), which
slows the system down. Then, one has to employ
tricks to improve their tail latency.
Quiescent consistency components can be combined to form quiescently consistent components again. Note also, that strong consistency implies quiescent consistency, hence you can combine these two kinds of systems, and the result will be quiescently consistent.
"Distributed" Consistency Models
Consistency is not Fault Tolerance
It may be tempting to mix the concepts of "consistency" and "fault tolerance". The former is how object reacts to method calls depending on the calling thread (or, in other words, how data are seen by multiple observers). Fault (or Partition) Tolerance describes how system behaves when system becomes partitioned, i.e. messages are lost, and/or parts of the system get disconnected from the network, or form several networks. These concepts are orthogonal to each other: an object can have one of them, both of them, or neither.
It will be, more likely, one of them. There is a scientific result known as CAP theorem that states that a system can't at the same time guarantee:
- Linearizability
- Availability (whether RPC calls send replies)
- Fault Tolerance
In this post, however, we will focus on consistency rather than other properties of distributed systems. Note that multithreaded systems due to close proximity of their components, and less versatile medium that connects them, do not have to worry about fault tolerance...at least, at the current state of art.
The following models are usually seen in the context of distributed systems, i.e. those that reside on multiple machines, communication between which is slow enough. To bring Object-Oriented abstraction to distributed systems, programmers invented "Remote Procedure Call" (RPC) pattern. Method calls (object identifiers, method name, and arguments) are encoded into messages that are then sent across the network to specified destination, which may be the part of the encoding too. Method calls that do not expect a reply (say, unreliable "fire-and-forget" writes) may be treated as instantaneous.
Eventual Consistency
A system is eventually consistent if the method calls can be correctly arranged in a sequence
that retains the mutual order of calls separated by a sufficiently long period of time. The
"sufficiently long period of time" is system-specific.
Usually, eventual consistency is combined with sequential consistency, in a
stanza like: "the data written to the database is immediately visible from the same process and eventually
visible from other [concurrent] processes".
The eventual consistency definition—as well as its understanding—is intentinally vague on how much time it would take, and whether this time depends on the call history. We can't really tell how soon an eventually consistent set will respond that an element X exists in it after it was added. But "eventually" it will.
This looks quite useless from a mathematical perspective since the loose definition doesn't help draw
conclusions. What is it used for then? Well, users usually expect strong consistency from a system,
and if it is different, it needs to be pointed out. Eventual consistency is actually a limitation of liability; it's used to convey that the system can't guarantee that different threads become in sync immediately. However, the system is engineered in such a way that they eventually take effect. Here's an example (here's more on eventual vs. strong consistency)
Some authors, according to wikipedia, require that no method calls should be invoked during the "long period of time" for system to get in sync. This actually sounds like a stronger version of quiescent consistency, where a qualifying quiescence should be long enough.
Strict Consistency
An execution is strictly consistent if the method calls sorted by completion time are correctly ordered.
This is as simple and powerful as it's impossible to attain in most practical systems that have more than one thread. First, it order calls according to "global" time, which is a purely mathematical abstraction unachievable in real life, both according to Physics, and to the theory of distributed computing. Second, any implementation I might imagine would essentially disallow multithreading per se.
This is my rendition on the more "official" definition (1, 2), which defines a strictly consistent system as one where any read operation over a certain item returns the value supplied to the latest write operation according to global time counter. I don't like this definition because it needs to distinguish between "reads" and "writes", and introduces the concept of "data item"—i.e. it breaches the object-oriented approach. Still, I'm sure that if the system really consists of "data items," the definition at the beginning of the section would work as well.
Serializability
An execution is serializable if its methods in each thread are grouped in contiguous, non-overlapping transactions, and the methods can be correctly ordered in such a way that transactions are still contiguous.
In other words, the outcome of a sequence of method calls can be described as a serial execution of transactions, where methods of different transactions are not mingled, while the transactions actually overlap in time across different threads.
The useful outcome here is that calls within overlapping transactions can be reordered, even if they don't overlap. However, "serializability" is not enough to describe the system: while it limits reordering of methods across transactions, it is unclear to what extent transactions can be reordered themselves. This is a job for a different consistency model. And serializability is usually used to "remind" about this important property of transaction-based systems.
Practice
Some systems provide several levels of consistency for operations (like the App Engine's High-Reliability Datastore linked above). You should understand what tradeoffs each model has to make the decision best suitable for your specific application.
Most system you encounter will be not consistent at all ("thread-unsafe"), or linearizable (this is what usually understood by "thread-safe"). If the consistency model differs, it will be noted explicitly.
Strictly speaking, most systems that claim linearizability will be not consistent due to bugs, but these nasty little creatures aren't suitable for careful scientific discourse anyway.
Now that you know what consistency models are out there (and that they actually exist), you can make informed decisions based on what's specified in documentation. If you're a system developer, you should note that you are not bound to choose between linearizability and "thread-unsafety" when designing a library. The models presented above may be viewed as patterns that enumerate what behaviors in multithreaded context are considered universally useful. Just consider carefully what your users need, and do not forget to specify which model your system follows. It will also help to link to something that explains what lies behind the words "somethingly consistent" well--like this post, for instance.
Comments imported from the old website







Many thanks to Martin Ward who pointed to inaccuracies in termination proof description.