Ruby on Rails is a web application development framework most known for its flexibility and heavy use of metaprogramming. Rails programs, as one of my peers described, "look like they explain what to do rather than how". That's true. This declarative nature of Rails, however, comes at a cost. At a cost of performance, of course.
A couple of days ago, I was developing a tree-shaped web board engine (some of you have probably forgot what these are; here's the engine I'm creating a clone of). I designed a data model for users, authorization, threads, messages, message revision history, etc, and implemented a comprehensive set of operations with them, such as creating, displaying, editing, and so forth. The implementations looked nice; it consisted of carefully engineered bits of declarative programming.
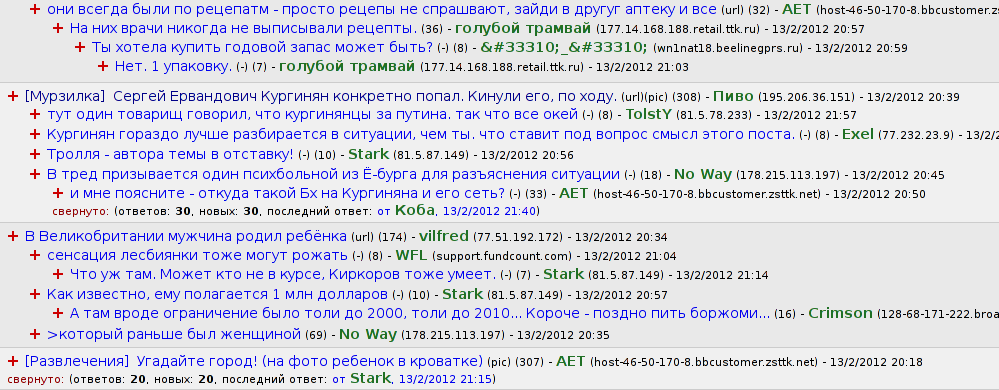
This is how the index page of the forum should look like:
You may notice that all messages from all threads are displayed However, when I tried to display several thousands of messages on a single web page, which is an average figure for an board like this, it appeared deadly slow. Nobody would wait 32 seconds for the index page to show. Caching would help, but as several messages are posted each minute, most cache accesses would be misses.
In the rest of the post, I'll show you how the speed of page displaying and rendering may be increased by a factor of 50 (fifty).
Data model
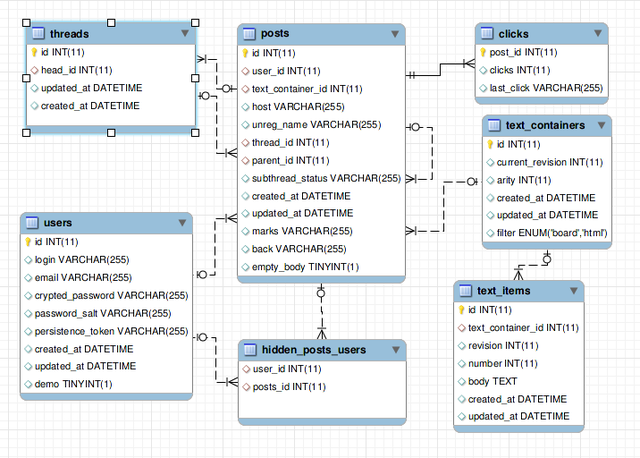
The key source of why the original speed was so surprisingly slow is that I designed a database layout that fits a relational database requirements, in which the data span across several tables that may be join-ed. The query to display the whole information should thus not be slow to achieve. Here's how it looked like:
The image above was generated with "MySQL Workbench" tool. If you supply a database with properly set up foreign keys, which I did manually, as Rails doesn't set them up for compatibility reasons, it will show you a nice entity-relationship diagram.
The messages to display consisted of the posts made to the newest threads, which were created within the last day. It's obvious that you could get all the necessary information from the database with a single SQL query with a lot of joins though, but no unions, the query being executed negligibly fast by even the "default" MySQL server. Why was it so slow?
How Rails make you program slower
There are two main reasons why the naïve way of displaying these posts was slow. By the "naïve way" I mean a simple view that renders each post and its parameters by querying its association attributes, like this:
You saw the tree that should appear as a result of this above.
How the controller would look like for this view? Due to database design, it should select a thread, and render a tree of its root (head) post. So the controller would look like:
So, what happens when a view is rendered? For a single thread, all messages are fetched by a single SQL query, and are converted to an array. The ActiveRecord has_many association within a thread object automatically does this; this operation is relatively fast. Then, we assemble a tree structure of the posts (it works very fast, and is not shown here; the result is returned by the build_subtree method), and render these posts in the proper order.
Trying to render a post, Rails encounters its title function that queries the latest revision of a post's title. This query is resolved as querying the TextContainer, and, subsequently, the TextItem with number = 1, and revision matching the latest_revision of the TextContainer. Then the same is repeated when Rails renders the post's user name: it queries user object for each of the posts separately. Therefore, for each post, Rails performs three separate queries to the database, each involving the whole ActiveRecord's overhead for initiating a query, finalizing it, and packing the individual objects.
These multiple and excessive database requests, followed by the subsequent conversion from SQL to "heavyweight" ActiveRecord models, contributed to approximately 25 out of 32 seconds of inefficiency at each call. Let's try to optimize them.
Optimizing ActiveRecord queries
One might infer from the reasoning in the previous paragraphs that ActiveRecord is just a bad framework for ORM. This is not true in two ways. First, the main objective of ActiveRecord is to provide an ORM that works with little configuration, or even without configuration at all. Second, ActiveRecord is mainly used for representing single-table models; in our case, however, we deal with data representation that spans several database tables.
This suggests the way to fix performance here. Indeed, we already noted that all the data required to represent the tree of posts, may be fetched with a single SELECT query. We can create an ActiveRecord model designed specifically for this query (you may call it a "view" if you like) reaping the benefit of having no configuration alongside. In the view, we alter the methods that query the information, so that they match the fields
We don't even have to alter the way the properties are queried in the view by introducing fake "proxy" objects to our new model, like this. table_tow.user returns a simple object that has a login method initialized with a value from the query. In my case that would be an overkill, but if you have a lot of views to fix, you may explore such an option.
In the case of the view presented above, we'll need the following fields, id, title, created_at, empty_body (instead of body.empty?, see sidenote), marks (which is a serialized array automatically maintained by Rails' serialize class method), unreg_name, user_login (instead of user.login, see sidenote), host, clicks, hidden. Not shown directly in the view, but used to build the posts tree is parent_id field. We'll call the model to comprise these fields FasterPost, and start with an empty model stored in app/models/faster_post.rb:
These posts will be fetched via Thread class. We already had a has_many association "Thread has many Posts", and we modify it using a standard :finder_sql attribute:
The settings_for is a global helper that denotes the current user, we'll return to it later.
While :finder_sql was originally used for slightly different purpose, we piggyback on its ability to execute arbitrary SQL query (ActiveRecord has only two such ways, the second is find_by_sql).
Let's try to fetch data bia this association, and we'll see an exception:
Mysql2::Error: Table 'database.faster_posts' doesn't exist: SHOW FIELDS FROM `faster_posts`
The original post model has a plural name (Posts) because the ruby standard library contains the singluar Post
Indeed, ActiveRecord doesn't know what columns there should be in the resulting table. We need to override a couple of methods; as of Rails 3.1.3, these are columns, and columns_hash. These methods are not really used, and we need to supply some ActiveRecord's internal structures for that. Instead of supplying the actual column information for our raw SQL, we simply copy the column information from Posts model (and cache it, as ActiveRecord itself does):
When we try to serialize this model for debugging purposes via the inspect method, we'll see that for our model is not really useful: it doesn't show all the fields. We may find the original Object's inspect method useful here:
That's all what's needed to make this model work (see sidenote for one more subtle issue). However, we may find out (with the profiler) that we still spend a lot of time inside some ActiveRecord methods. When a field method is called, it still gets through some ActiveRecord internal checks and conversions, which take a lot of time, and are, basically, useless for our lightweight model. Even that we have to enter method_missing to route the method to the actual field slows us down.
I found that ActiveRecord has a method that is close enough to the data fetched from the table, but it doesn't perform some conversions (for instance, boolean values are not converted, and are fetched as strings instead). It is read_attribute_before_type_cast (note, that its attribute should be a String, not a Symbol!). So, each fast field method should directly call it as "short cut". We can generate these methods for all the query fields with Ruby metaprogramming capabilities:
Do not forget to add overrides, which should be declared after this call, for methods that require additional processing (such as serialization):
or return Boolean or Integer values:
After these fixes are put in place, and the view is altered accordingly, all the database queries will not take any significant time. Moreover, this solution also complies to Model-View-Controller pattern, as the data are fetched in the controller, before the view is rendered. This is, probably, one of the rare cases when compliance to the Design Patterns does boost performance.
This, originally, decreased the original runtime by approx. 20 seconds out of 32. But there still are 12 seconds to optimize away. How could this be done?
Optimizing the view
ActiveRecord optimization is not enough, though. A lot of time is spent in the view itself. I had to use a profiler to do that, and made several wondrous discoveries. Using profiler is quite simple in Rails 3. All you have to do is to start a server, and invoke in the console
$ rails profiler -r 5 'get("/")'
and open tmp/performance/ProfilerTest#test_get_process_time_graph.html in your browser. An annoying downside is that it prints its log to the server's console (but you're not trying to do anything while profiling, are you?) Here are several points to optimize I found.
Link Generation with link_to
One of the greatest offenders was the code that generates links. The usual link_to and autogenerated path methods, such as post_path(post) are very slow, compared to the rest of HTML-generating code. However, if we try to generate URLs in our view on our own, it may no longer be enough to edit config/routes.rb to change all the methods in the application. We'll lose the flexibility of Rails we love it so much for!
Instead, I used a kludge for link generations. I assumed that links to all posts look the same, and the difference between them is only the post's ID. Therefore, if we generate a link for one post the Right Way (with link_to and ..._path functions), dismantle it, and create other links as simple string concatenations from the resultant parts, we'll avoid this overhead. Here's the helper I created:
It creates a link generator that generates the link in the fast way, provided all the links are the same. Calling this method from the view is as clean as calling the link_to:
The method returns a proc object (function), and brackets are used to call it with post parameter.
Authorization
Declarative Authorization is a very nice plugin to manage authorization. It's declarative, and is very convenient to use once you carefully read its manual, and start naming your before_filters by its rules. However, I found out that it's terribly slow when you are to query authorization rights for thousands of posts.
I merely got rid of authorization at the index page, and moved it to a page of individual posts. But you could add more JOINs to your SQL, fetch user roles, and write some lightweight authorization methods instead, if you really need it.
Another way to optimize authorization could be the same kludge that was used in Links optimization. In most cases, if you are authorized to delete a post, you are also authorized to delete all posts in this threads (or in the whole forum). You can try to piggyback on these assumptions.
User-specific settings
How could we optimize user-specific settings on a large scale? Here's the excerpt from the view code I'm referring to:
This excerpt implements user's functionality to show/hide posts in its own view, not affecting what other users see. In the big SQL statement above you could notice that we join the hidden_posts_users to fetch the user-specific settings. Here we also encounter the same problem that with the links, but the "simple" link generator should be slightly more complicated:
but its usage will become even simpler:
Note that wile you supply the block that translates the strings thousands of times to the fast_hide function, it will be called only once, at the very beginning.
Translations
I won't dive into here too much, since it's obvious that you should not call t method that translates a string according to the current locale thousands of times for the same string. Save the result of a single call into a variable, and re-use it. It won't change as you render parts of your view anyway.
However, this doesn't save you really a lot of CPU cycles. I found out that calling t("Show subtree") (see the example above) approximately 2500 times only takes 0.05 seconds. But if you multiply that with the number of strings you have to translate, this may grow large.
Caching serialized attributes
The default (de)serialization procedure for ActiveRecord's serialize generator does not cache its results. Caching may not be useful in all cases, of course. However, in my case, there was a total of four possible values for the serialized column ("the post has/has not a picture/a link inside"), and thousands of rows. To use caching (and short cut some ActiveRecord's default useless code), you should just pass your own serializer to the method:
I'm not sure that this behavior is documented (I extracted it from the code, and can't find anything about it in the help), but it works.
Avoid excessive render calls.
This may not be the case for you, but if you call render :partial thousands of times, this just can't be fast. Instead, use a single partial template that renders many items at once. My measurements show that this may save up to 20% of ~ 11 seconds runtime.
If your template is recursive, and you user HAML (not ERB), you'll probably have to move your code in some cases to a helper, and print raw HTML in order to keep the markup (for instance, if you use recursively-folded lists).
Raw HTML instead of Templates
If it's still not fast enough, you may print raw HTML. I don't have any measurements of the effect of this operation alone, but you may try that. This will clean up your profile, and you'll see the offenders more clearly
Make sure to use String Buffer pattern (as I encountered it in many languages, I can call it a pattern). Instead or using + operator to concatenate strings, allocate a buffer string, and append other strings to it. In some languages, such as Java or OCaml, it's not enough, and you should use a separate StringBuffer objects, but, in Ruby, Strings are mutable, and any string may serve as a buffer. By the way, HAML templates are already aware of this pattern (and, I guess, ERB templates are, too), so this only should be used if you already chose to print raw HTML on your own by other reasons (such as described in the previous section).
Other speed increase advice
As you might have noticed, my blog is very slow. It takes about 2 seconds to render any page. The blog was my first Ruby on Rails application ever, so it surely had some design mistakes. On the other hand, three years ago, Rails (version 2 at that time) was much less mature than today, and many speed improvements, such as monadic database querying, was only introduced in version 3.
I figured out the reasons why the rendering is slow, but today I just don't have enough time to fix the code. I'll just describe what mistakes I made and how to avoid it.
Touch your parents when you change!
A good advice in the real life as well, touching parents is also a good practice in Rails. Assume that you need to sort threads by the update time of a thread (I'll use the forum data model as an example). An update time is a time of creation of a post in a thread, or an update time of a post in the thread. When we click "edit" on a post, and complete updating it with save call, the default behavior is that the updated_at field of the post's database record is updated to the current time.
The updated_at record of the thread, however, is not updated automatically. Unless you do this, you will have either to write SQL queries, or just to load all threads, and check all posts for each of them. Rails' belongs_to association has :touch option, that will make it automatically "update" parents when you save children. This will solve the problem of fetching updated threads with little effort.
If you have an abstract "content" type, so that all text items on your site are stored and edited in a uniform way, you will find that :touch neatly integrates with polymorphic associations.
Unfortunately, :touch is only included in Rails 3.
Use monadic database queries
I used to fetch the last blog post in my engine by blog.posts_ordered.first, where posts_ordered is a non-standard ordering of posts. It first fetched all posts, reordered them, and selected the first, which was overly inefficient.
The solution to that would be monadic queries (see find method documentation). Rails 3 allow you to "chain" database queries joining the conditions without executing the query. After you chained all the queries, you may "bind" the query object, and execute the query. It will look like this:
Only one post will be fetched and converted into the ActiveRecord object this way.
Unfortunately, this is only included in Rails 3. In Rails 2 I had to write my own "monadic" query wrappers.
Slow and Loving It
For many cases, however, the performance of Rails is good enough. It can't compete with pure C++ web applications, of course. Rather, Rail's stronger side is describing complex behavior with little effort, with just a few lines of code. A lot of problems I encountered were due to bad performance of overly complicated data models, or with showing thousands of records on a single page. Rails is not unique in such poor performance; for instance, it takes Bugzilla 3 (written in Perl), like, 20 seconds to show a bug with seven hundred comments.
The cool thing in Rails, however, that it's a flexible framework. If you really need to display a thousand of records fast, you can do it. Nothing in the framework prevents you from creating shortcuts to its low-level functionality (Ruby language plays an important role in this), and nothing prevents you from swapping its parts with your own fast code pieces, where it's really necessary. In the forum engine I used here as an example, only a couple of views should display thousands of records. Optimized models and views may be only assigned to these "hot parts" of the application. The rest of functionality, at the same time, takes the whole benefit of the easily configurable framework, of declarative coding, and of rapid feature development, everything I love Rails for.




















Oh my god! You hacked the airplane!!!!