This blog is now a Hugo-powered static website on AWS Elastic Beanstalk
Ten years ago, I thought this website should be a content platform with video hosting, blog platform, and other cool things. It was an essential learning experience: I’ve chased performance bugs and reinvented highload wheels. Today, armed with several years of Industry Experience™, I am ready to present the highest-grade advice of a seasoned web engineer.
The right architecture for this blog is a set of static webpages served off of a file system by a simple web server such as Apache or nginx. One tiny shared VM would serve way more visitors than my content could ever attract.
And I did just that. There’s no dynamic content here anymore. So… wordpress you say?
Why do this again?
I hated managing the website manually, so why did I choose to endure one more manual-ish setup? First, Wordpress is for wimps who love PHP, especially the hosted one. I was going to yet again immerse into whatever the current hype was in order to learn about the latest cool tech. And the hype of 2017 was
- container-based (Docker)
- mobile-first
- implemented in Go
- deployed onto Managed Cloud
- with managed services for email, database, etc
- …and maybe even serverless?
Everyone seems to like Amazon. I would have chosen Google Cloud Platform, of course, if I were to optimize for quality and reliability. However I’ve chosen AWS because its a) the hype; b) not where I work. I’ve had enough exposure to Google Cloud as an insider, and I did want to expand my horizons.
But how would I choose what exactly to do? What should my architecture achieve? Of course, it should be security, long-term maintainability, and… money.
Security
My previous version of the blog ran on Gentoo Linux. It was hell and it became unmaintainable. I rant about it at length in my previous post.
Anything that is quickly updateable would work. I used whatever linux. I literally don’t remember what it is; I need to look….
$ head -n 1 Dockerfile
FROM nginx:latest
What is it? I guess it’s Ubuntu or something else Debian-based, but I literally don’t care. Ok, Security–done, next.
Let’s optimize for… money!
Another motivation I had was to reduce the cost. Before the migration, the single VM that was serving my shitty Ruby on Rails app cost ~\$50 / month. Gosh, I could buy a brand new computer every year. So, can I do better than to shell out the whopping \$720 / year for this website few people read? Can I do, say, \$10 or \$20/month?
It sometimes gets worse. As the fascinating Interview with an Anonymous Data Scientist article puts it,
…spot prices on their GPU compute instances were \$26 an hour for a four-GP machine, and \$6.50 an hour for a one-GP machine. That’s the first time I’ve seen a computer that has human wages…
Turns out, I could get it cheaper but only if I didn’t use all the managed services. Managed is costly.
The smallest (tiniest) MySQL managed database costs \$12 / month on AWS. It supplies me with 1 cpu and 1 Gig of memory. This blog doesn’t need 1 damn CPU dedicated to the DB! It doesn’t even need a DB! It needs to copy static pages from basic file system to your screen!
Rabbit holing is another problem. So what if I want a AWS managed Git? Yes sure! That’d bee free or \$1 a month. Plus access to the Keys. The Keys would be \$1/month. Oh, and the logging of the key usage? That would be another whatever per access unless there’s 10k accesses but don’t worry, for most workflows that’d be fine!..
ugh. Can I get something more predictable? One way is to search clarity, and the other to get rid of this.
Getting rid of this. And of that.
Turns out, I can get by on the internet with free services for code storage, bug tracking, and file, photo and video storage. The \$1/month I pay to Google covers 100 Gb of crap, which I’m yet to fill. GitHub and Youtube are the staples. I’ve explained more on private git and other things in the previous post.
Do I even need rendering?
So what about converting human-writeable rich-text formats to HTML? Wordpress would be too lame, but I can’t do my own rendering engine anymore. The highlight of the previous version was of course the custom context-free parser generator that compiles a formal grammar into Ruby code. It took it sweet 1-2 seconds (!) to render each page of this website (not a joke).
That thing burns in hell and gets replaced with Markdown.
There would be no database. The contents (i.e. the text on this and other pages) would be versioned in Git and stored on a “local” disk (disks that are attached to only 1 machine are considered local even if they are actually remote, which is how cloud architectures now work).
If I wanted to change the contents or to post something new, here’s what my workflow would look like:
- SSH onto the server
- Use vim to add or edit a file in a special folder.
- Use git to push the change into the “release” branch.
- Run a ruby script that would use Markdown to format all the blog pages
into HTML. It would use
lsto get the list of all pages and make the blog archives page. That’s not much different from a DB-based architecture: ater all, Databases evolved out of simple collection of files arranged into folders. rsyncthe code onto the remote disk.
That’s it. nginx would serve the generated pages. Since making a new post invalidates all pages
anyway because you’d see it pop up in the sidebar to the left, there’s even no need to be smart
about it!
What a genius idea! It’s so obvious that I’m surprised nobody…
…and here’s a list of 450 static site generators
…welp.
I chose Hugo because I wanted to play with Go.
Well, ok, now what do we do with Docker?
Docker can combine the local disk contents with a recipe called Dockerfile to produce a VM-like image that could serve a website.
Now, it would be a fun idea to have a self-hosted Docker image. The image would contain the Git repositories for website content and its own Docker files, and it would build itself and redeploy itself using AWS APIs. I think it could work…
But let’s start with something simpler. Let’s simply build Docker from another Docker container. It’s easy enough and it protects me from the loss of my home machine. In the end, the workflow would work like so:
- Docker image
Buildcontains all the build tools, including the Hugo website builder. - Static contents (including the images and Markdown files) are in a git-versioned local folder.
- The
Buildimage runshugoto create a folder with HTML, CSS, and other files that constitute the entirety of the website. - Another Dockerfile describes the “Final” image, which combines [nginx:latest][nginx-docker] and the static files created in the previoius step.
- The Script deploys it to Amazon Elastic Beanstalk.
- a Makefile connects it all together.
Here’s a diagram of what it looks like:
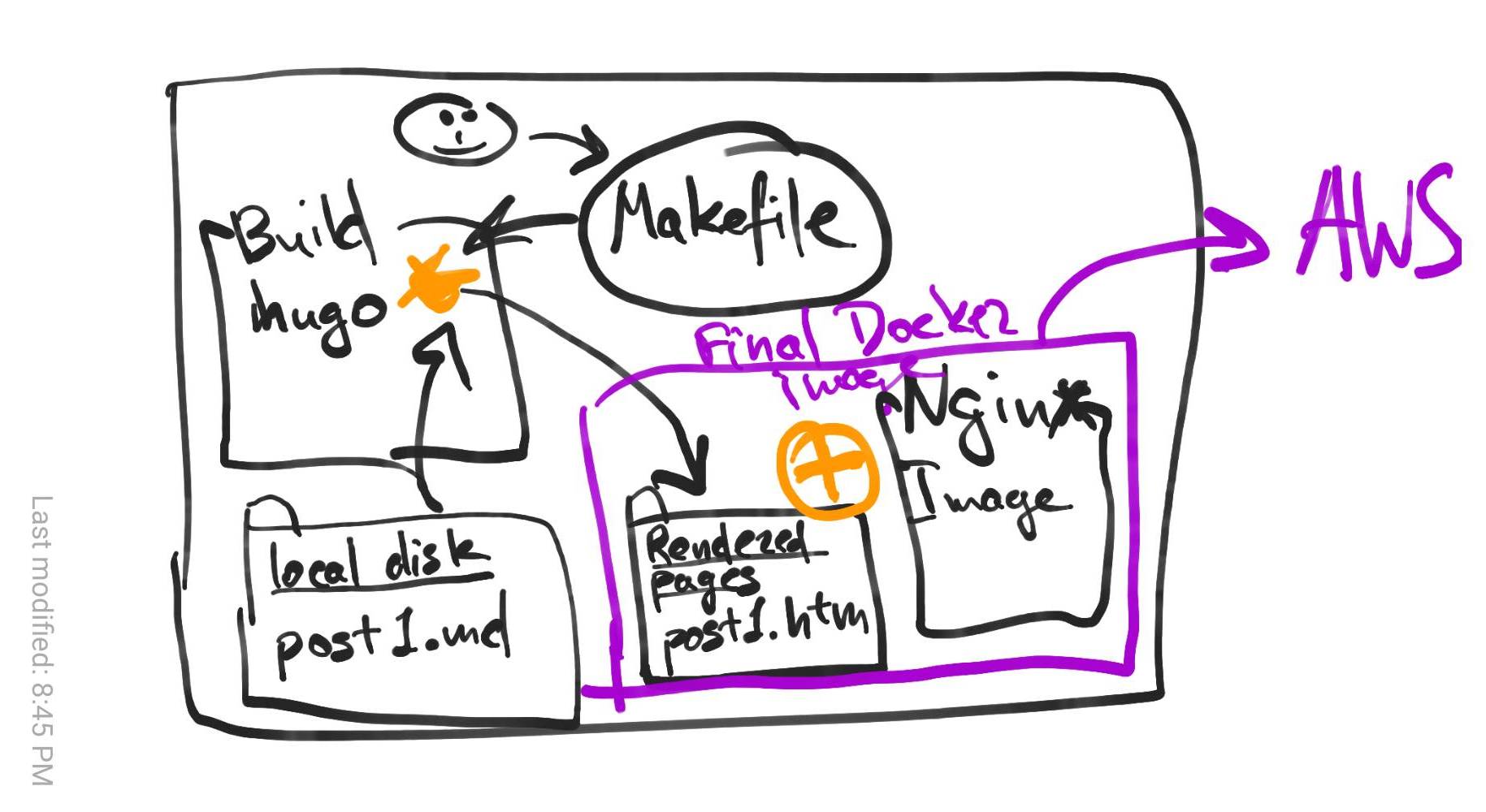
And in the end, you get this website.
Amazon Elastic Beanstalk speed run
The speed run of how to set up autoscaled container service on Amazon Cloud is in a separate post.
A speed run is a playthrough of an otherwise fun game done as fast as possible (primarily, on video). Setting up AWS is a very fun game. For example, it's easy to set up ECS, and then discover, halfway through, that you've made some wrong choices at the beginning that are unfixable, and you have to start over.
I wrote a speed-run of AWS Container game. Check it out, and after that you can enjoy speed runs of less fun games on youtube.
But did it work?
Yes it did.
It works, it is blazingly fast, and it’s pretty cheap for a managed platform with rolling updates. My bill is \$0.85 per day, which brings it to… $26 a month. In a quirk of Amazon Billing, it says I’m paying the most (65%) for the Load Balancer rather than for “running the instances” (27%). All these costs are bogus anyway.
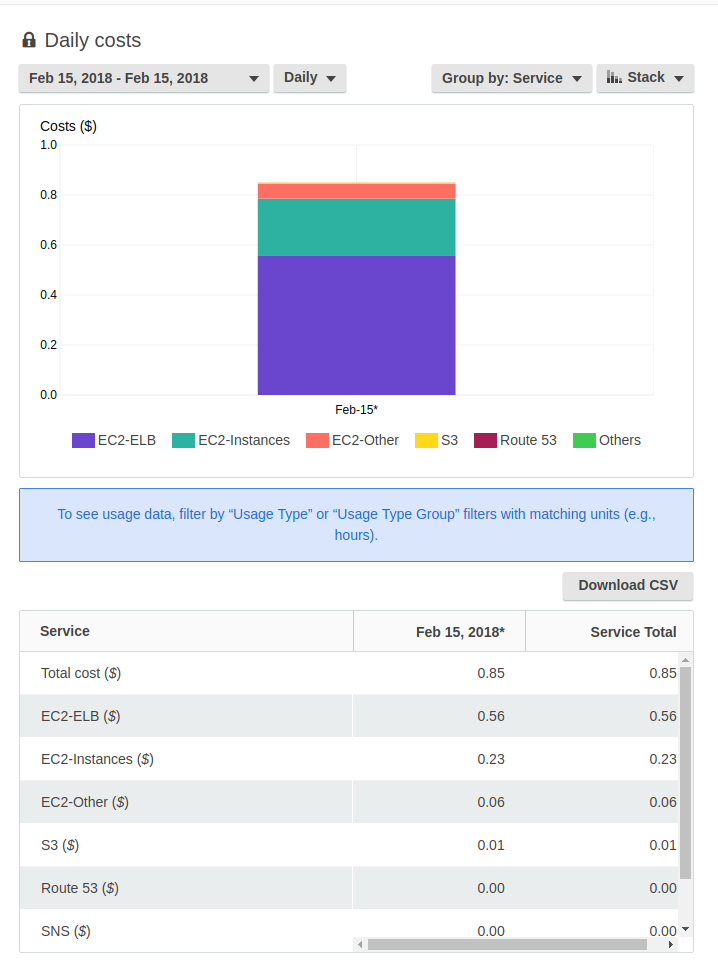
Believe me, I tried to delete the Load Balancer (this kills the service) or switch to single-instance configuration (this simply doesn't switch and quickly reverts back--sic!). I couldn't bring it below \$25, and I'm OK with that. Although, I could run this on App Engine for free...
I’ve achieved my goals: cut costs by almost a factor of 3, and reduced the page load speed by a factor of 10-100x.

I fixed my blog. But I set out to fix it not to blog about fixing it; I wanted to explore something more interesting. But perhaps, next time. ;-)










I'd prefer using some kind of ADC (http://en.wikipedia.org/wiki/Analog-to-digital_converter) to measure analog signal level.